
The stateful control plane for AI agents. Track, secure, and optimize every agent run with absolute visibility and control — not just individual LLM calls.
Works with multiple LLM SDKs (Anthropic, Gemini, OpenAI, Cohere, Mistral, LiteLLM, etc.) and agent CLIs like Claude Code, Gemini CLI, and OpenClaw.
Standard AI gateways operate at the LLM call level — they see each API request in isolation. But modern AI agents run in loops, have specific sessions for individual tasks, make 50+ background calls, frequently crash, and what not.
StateLoom is session-aware and built explicitly for agents. We group fragmented workflows into meaningful, stateful sessions. This allows you to resume crashed scripts without paying to repeat previously successful steps, enforce strict budgets across entire workflows, contain the blast radius of rogue agents, and gain absolute transparency into what your models are doing behind the scenes.
Most importantly, StateLoom is designed for absolute data sovereignty. Because it runs locally on your laptop or directly inside your enterprise network (VPC), it functions as an isolated, zero-trust control plane ensuring your data never passes through a third-party SaaS proxy.
- Why StateLoom?
- Install
- Quick Start
- Providers
- For Individual Developers
- For Teams & Enterprise
- Key Examples
- Dashboard
- Extras
- Configuration
- Error Handling
- Documentation
- Contributing
- License
pip install stateloomRequirements: Python 3.10+ (tested on 3.10, 3.11, 3.12, 3.13). See extras for optional dependencies.
pip install stateloom
stateloom start
# Dashboard is live at http://localhost:4782Or use it in your code, wrap your regular calls within stateloom session or use stateloom.chat(model="gemini-2.5-flash", messages=[...]) directly.
stateloom.init()
claude = anthropic.Anthropic()
with stateloom.session("customer-report", budget=2.0, durable=True) as s:
research = claude.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=[{"role": "user", "content": "Key trends in AI governance 2025"}],
)Auto-detects and patches installed LLM clients:
| Provider | Package | Auto-patched | Streaming |
|---|---|---|---|
| OpenAI | openai |
Yes | stream=True |
| Anthropic | anthropic |
Yes | stream=True |
| Google Gemini | google-generativeai or google-genai |
Yes | generate_content_stream() |
| Cohere | cohere |
Yes | chat_stream() |
| Mistral | mistralai |
Yes | chat.stream() |
| LiteLLM | litellm |
Yes | stream=True |
| Ollama (local) | — | Via local_model= |
— |
StateLoom gives solo developers and startups everything needed to build resilient agents locally, for free. Here is what you can get out of using stateloom SDK.
Agent Cost Control
- Session-scoped cost tracking — cost per agent run, not just per API call
- Per-model cost breakdown — track cost and tokens per model within multi-model sessions
- Budget enforcement — hard stop or warn when an agent run exceeds its spend limit
Agent Safety
- PII detection — detect emails, credit cards, SSNs, API keys (audit/redact/block modes)
- Guardrails — prompt injection detection (32 heuristic patterns + NLI classifier + Llama-Guard), jailbreak prevention, system prompt leak protection
- Zero-trust security engine — CPython audit hooks (PEP 578) to intercept dangerous operations + in-memory secret vault
Performance & Caching
- Exact-match & semantic caching — deduplication plus embedding-based similarity matching
- Loop detection — catch agents spinning on the same query
- Session timeouts & cancellation — max duration, idle timeout, and programmatic cancellation
Local Models & Smart Routing
- Local model support — run Ollama models locally with hardware-aware recommendations
- Intelligent auto-routing — route simple requests to local models based on complexity scoring
- Model testing — test candidates against your production model with automated quality scoring and migration readiness reports
Agent Reliability
- Durable resumption — Temporal-like checkpointing: agent crashes mid-run, restart, resume from cache
- Semantic retries — automatic retries for LLM output failures (bad JSON, hallucinated tool calls)
- Time-travel debugging — replay a failed agent run from any step with network safety
- VCR-cassette mock — record LLM calls once, replay forever for zero-cost testing
- Named checkpoints — mark milestones within a session for the dashboard waterfall timeline
Multi-Model & Experimentation
- Multi-agent consensus — vote, debate, and self-consistency strategies with up to 3 models
- A/B experiments — test model variants with built-in assignment, metrics, and backtesting
- File-based prompt versioning — drop
.md/.yaml/.txtfiles in a folder; auto-detect changes as new versions
Developer Experience
- Unified chat API — provider-agnostic
stateloom.chat()without importing any SDK - Session export/import — portable JSON bundles for sharing, archiving, and migration
- LangChain / LangGraph integration — callback handlers for popular agent frameworks
- Local dashboard & REST API — live session viewer, security controls, observability charts at
localhost:4782
Agent CLI Integration
You already pay for Claude Pro or Gemini Ultra. Use your existing subscription through StateLoom — get cost tracking, PII scanning, budget enforcement, guardrails, and a session timeline for every agent run. No API key needed, no code changes.
stateloom startexport ANTHROPIC_BASE_URL=http://localhost:4782
claude "explain this codebase"
# All calls appear as one session in the dashboardexport CODE_ASSIST_ENDPOINT=http://localhost:4782/code-assist
gemini "refactor the auth module"export OPENAI_BASE_URL=http://localhost:4782/v1
codex "add unit tests for the auth module"All CLIs connect to the same StateLoom instance. Subscription users (Claude Max, Gemini Ultra, ChatGPT Pro) work transparently — OAuth tokens pass through to the upstream provider.
StateLoom Enterprise Edition (EE) provides a single, centralized control plane to govern, secure, and optimize your entire AI workforce. We give engineering and finance teams absolute visibility into hierarchical org and team-level token billing, paired with centralized Virtual Key management and strict budget enforcements to automate chargebacks and prevent runaway costs. Accelerate your AI roadmap by empowering teams to spin up agents in secure, isolated sandboxes within your own private ecosystem, safely run live A/B experiments, validate cheaper models via risk-free dark launching, orchestrate high-assurance multi-agent consensus, and auto-generate proprietary training datasets through our distillation flywheel. Simultaneously, we provide your CISO with a unified zero-trust security perimeter: an in-memory Secret Vault, real-time prompt guardrails, declarative compliance profiles, dynamic force re-routing, and a global kill switch to instantly contain the blast radius of rogue agents. There is so much more you get. And the idea behind all of it is for you to keep the full control of the agents while allowing you to scale seamlessly.
👉 Book an Enterprise Demo Today
import stateloom
import anthropic
import google.genai as genai
stateloom.init()
claude = anthropic.Anthropic()
gemini = genai.Client()
with stateloom.session("customer-report", budget=2.0, durable=True) as s:
# Step 1: Research (Claude)
research = claude.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=[{"role": "user", "content": "Key trends in AI governance 2025"}],
)
# Step 2: Analyze (Gemini)
analysis = gemini.models.generate_content(
model="gemini-2.5-flash",
contents=f"Analyze: {research.content[0].text}",
)
# Step 3: Synthesize (Claude)
report = claude.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=2048,
messages=[{"role": "user", "content": f"Write report: {analysis.text}"}],
)
print(f"Total: ${s.total_cost:.2f} | {s.total_tokens} tokens | {s.call_count} calls")
# Mix providers freely — StateLoom tracks cost across all of them in one session.
# If this script crashes on Step 3, restarting it skips Steps 1 & 2 for free.
# Budget enforcement stops the whole run if it exceeds $2.from stateloom import PIIRule
stateloom.init(
pii=True,
pii_rules=[
PIIRule(pattern="credit_card", mode="block"),
PIIRule(pattern="email", mode="redact"),
],
)stateloom.init(
guardrails_enabled=True,
guardrails_mode="enforce", # "audit" or "enforce"
guardrails_nli_enabled=True, # NLI classifier (~5-20ms, optional)
guardrails_local_model_enabled=True, # Llama-Guard via Ollama
)
# Runtime toggle (no restart needed)
stateloom.configure_guardrails(nli_enabled=True, nli_threshold=0.8)stateloom.kill_switch(active=True, message="Maintenance in progress")
stateloom.add_kill_switch_rule(model="gpt-4*", reason="Cost overrun")stateloom.init(
security_audit_hooks_enabled=True, # CPython audit hooks (PEP 578)
security_audit_hooks_mode="enforce", # "audit" (log) or "enforce" (block)
security_audit_hooks_deny_events=["subprocess.Popen", "os.system"],
security_secret_vault_enabled=True, # Move API keys to protected vault
security_secret_vault_scrub_environ=True, # Scrub from os.environ
)
# Check status
status = stateloom.security_status()
# Store/retrieve secrets programmatically
stateloom.vault_store("CUSTOM_SECRET", "value")
secret = stateloom.vault_retrieve("CUSTOM_SECRET")stateloom.init(local_model="llama3.2:3b", auto_route=True, default_model="gemini-2.5-flash")
# No explicit model — auto-router decides local vs cloud based on complexity
simple = stateloom.chat(messages=[{"role": "user", "content": "What is 2 + 2?"}]) # → local
hard = stateloom.chat(messages=[{"role": "user", "content": "Design a consensus algorithm"}]) # → cloudstateloom.init(
shadow=True,
shadow_model="claude-haiku-4-5-20251001", # Cloud-to-cloud candidate
# shadow_model="llama3.2:8b", # Or local model via Ollama
shadow_sample_rate=0.5, # Test 50% of traffic
)
# Dashboard: localhost:4782 → Model Testing → see similarity scoreswith stateloom.session(session_id="task-123", durable=True) as s:
res1 = client.chat.completions.create(...) # Cache hit on restart
res2 = client.chat.completions.create(...) # Resumes hereresult = await stateloom.consensus(
prompt="What are the key risks of deploying LLMs in healthcare?",
models=["gpt-4o", "claude-sonnet-4-20250514", "gemini-2.5-flash"],
strategy="debate", # or "vote", "self_consistency"
rounds=3,
budget=1.00,
)
print(result.answer) # Final synthesized answer
print(result.confidence) # 0.0-1.0 confidence score
print(result.cost) # Total cost across all models
# Agent-guided consensus — all debaters use the agent's system prompt
result = await stateloom.consensus(
agent="medical-advisor",
prompt="Should we use AI for radiology screening?",
models=["gpt-4o", "claude-sonnet-4-20250514"],
strategy="debate",
)agent = stateloom.create_agent(
slug="legal-bot", team_id="team-1",
model="gpt-4o",
system_prompt="You are a legal assistant.",
)
# Call via: POST /v1/agents/legal-bot/chat/completionsstateloom.init(default_model="gpt-4o")
response = stateloom.chat(messages=[{"role": "user", "content": "What is the capital of France?"}])
print(response.content) # "The capital of France is Paris."Starts automatically at localhost:4782. Live session viewer, REST API, and WebSocket event streaming.
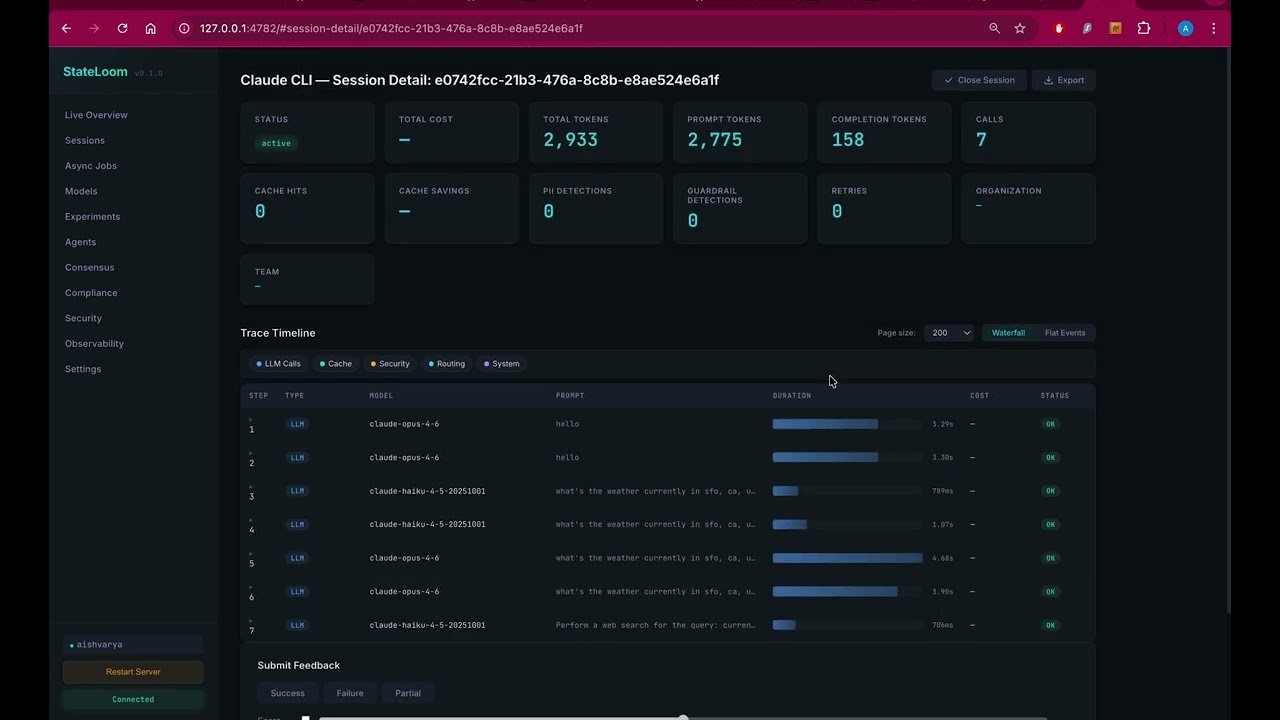
- Overview — total cost, active sessions, cloud/local calls, PII detections, guardrail detections, cache hits
- Sessions — list, detail with waterfall trace timeline, cost/token breakdown, child sessions
- Experiments — A/B test management, metrics, leaderboard
- Consensus — debate runs, round-by-round breakdown, per-model responses, confidence scores
- Model Testing — candidate model evaluation, readiness scores, quality distribution, filtering funnel, migration recommendations
- Safety — kill switch rules, blast radius status
- Security — audit hooks, secret vault, event log, guardrails (config, detection stats, violation history)
- Compliance — GDPR/HIPAA/CCPA profiles, audit trail
- Observability — request rate, latency percentiles, cost breakdo BE73 wn charts
See full API endpoint reference for all REST endpoints.
pip install stateloom[langchain] # LangChain callback handler
pip install stateloom[ner] # GLiNER NER-based PII detection
pip install stateloom[semantic] # Semantic caching (FAISS + sentence-transformers)
pip install stateloom[prompts] # File-based prompt versioning (watchdog)
pip install stateloom[auth] # OAuth2/OIDC authentication (pyjwt + argon2-cffi)
pip install stateloom[redis] # Redis cache/queue backend
pip install stateloom[metrics] # Prometheus metrics
pip install stateloom[tracing] # OpenTelemetry distributed tracing
pip install stateloom[all] # Everythingstateloom.init(
budget=10.0, # Per-session budget (USD)
pii=True, # Enable PII scanning
guardrails_enabled=True, # Prompt injection protection
local_model="llama3.2", # Enable local models + auto-routing
shadow=True, # Model testing
circuit_breaker=True, # Provider failover
compliance="gdpr", # GDPR/HIPAA/CCPA profiles
)YAML config is also supported:
from stateloom.core.config import StateLoomConfig
config = StateLoomConfig.from_yaml("stateloom.yaml")See full configuration reference for all options.
StateLoom is fail-open by default — observability middleware errors (cost tracking, latency, console output) never break your LLM calls. Security-critical middleware (PII blocking, budget hard-stop, guardrails in enforce mode) always fails closed.
For production security environments, set security middleware to enforce mode so violations block requests rather than just logging them:
stateloom.init(
pii=True,
pii_rules=[PIIRule(pattern="credit_card", mode="block")], # Fail closed: block on match
guardrails_enabled=True,
guardrails_mode="enforce", # Fail closed: block prompt injection
security_audit_hooks_enabled=True,
security_audit_hooks_mode="enforce", # Fail closed: block dangerous operations
)from stateloom import (
StateLoomBudgetError, # Budget exceeded
StateLoomPIIBlockedError, # PII block rule triggered
StateLoomGuardrailError, # Prompt injection / jailbreak
StateLoomKillSwitchError, # Kill switch active
StateLoomRateLimitError, # Rate limit exceeded
StateLoomRetryError, # All retry attempts exhausted
StateLoomTimeoutError, # Session timed out
StateLoomSecurityError, # Security policy blocked operation
)See full error reference for all error types.
- Full Feature Reference — detailed docs for every feature with examples, config tables, and YAML snippets
- API Reference — complete index of public functions, classes, and enums
We welcome contributions! Here's how to get started:
# Clone the repo
git clone https://github.com/stateloom/stateloom.git
cd stateloom
# Install in development mode
pip install -e ".[all]"
# Run tests
pytest tests/ -v
# Lint and format
ruff check src/
ruff format src/Guidelines:
- All changes need tests. Run
pytest tests/ -vbefore submitting. - Follow existing code patterns — use
rufffor formatting and linting. - Security-critical middleware must fail closed. Observability middleware must fail open.
- Events must be typed dataclasses inheriting from
Event. - Use
contextvars.ContextVarfor async/thread-safe state, not globals.
Reporting issues: GitHub Issues