Abstract
We introduce a novel machine-learning framework for estimating the Bayesian posteriors of morphological parameters for arbitrarily large numbers of galaxies. The Galaxy Morphology Posterior Estimation Network (GaMPEN) estimates values and uncertainties for a galaxy’s bulge-to-total-light ratio (LB/LT), effective radius (Re), and flux (F). To estimate posteriors, GaMPEN uses the Monte Carlo Dropout technique and incorporates the full covariance matrix between the output parameters in its loss function. GaMPEN also uses a spatial transformer network (STN) to automatically crop input galaxy frames to an optimal size before determining their morphology. This will allow it to be applied to new data without prior knowledge of galaxy size. Training and testing GaMPEN on galaxies simulated to match z < 0.25 galaxies in Hyper Suprime-Cam Wide g-band images, we demonstrate that GaMPEN achieves typical errors of 0.1 in LB/LT, 017 (∼7%) in Re, and 6.3 × 104 nJy (∼1%) in F. GaMPEN's predicted uncertainties are well calibrated and accurate (<5% deviation)—for regions of the parameter space with high residuals, GaMPEN correctly predicts correspondingly large uncertainties. We also demonstrate that we can apply categorical labels (i.e., classifications such as highly bulge dominated) to predictions in regions with high residuals and verify that those labels are ≳97% accurate. To the best of our knowledge, GaMPEN is the first machine-learning framework for determining joint posterior distributions of multiple morphological parameters and is also the first application of an STN to optical imaging in astronomy.
Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
For almost a century, starting with Hubble in (1926), astronomers have linked the morphology of galaxies to the physics of galaxy formation and evolution. Morphology has been shown to be related to many fundamental properties of the galaxy and its environment, including galaxy mass, star formation rate, stellar kinematics, merger history, cosmic environment, and the influence of supermassive black holes (e.g., Bender et al. 1992; Tremaine et al. 2002; Pozzetti et al. 2010; Wuyts et al. 2011; Schawinski et al. 2014; Huertas-Company et al. 2016; Powell et al. 2017; Shimakawa et al. 2021; Dimauro et al. 2022). Studying the morphology of large samples of galaxies at different redshifts is crucial in order to understand the physics of galaxy formation and evolution.
Over the last decade, machine learning has been increasingly employed by astronomers for a wide variety of tasks—from identifying exoplanets to studying black holes (e.g., Hoyle 2016; Kim & Brunner 2017; Shallue & Vanderburg 2018; Sharma et al. 2020; Natarajan et al. 2021). Especially, convolutional neural networks (CNNs) 15 have revolutionized the field of image processing and have become increasingly popular for determining galaxy morphology (e.g., Dieleman et al. 2015; Huertas-Company et al. 2015; Tuccillo et al. 2018; Hausen & Robertson 2020; Walmsley et al. 2020; Cheng et al. 2021; Vega-Ferrero et al. 2021; Tarsitano et al. 2022). Previously, we developed a publicly available CNN, called GaMorNet (Ghosh et al. 2020), which classifies galaxies morphologically with minimal real training data, and has been demonstrated to achieve accuracy ≳95% across multiple data sets.
This use of CNNs has been driven by the fact that traditional methods of classifying morphologies—visual classification and template fitting to the surface brightness profile of a galaxy—are not scalable to the data volume expected from future surveys such as The Vera Rubin Observatory Legacy Survey of Space and Time (LSST; Ivezić et al. 2019), the Nancy Grace Roman Space Telescope (NGRST; Spergel et al. 2013), and Euclid (Racca et al. 2016). The quality of fits obtained using template fitting depends significantly on the initial input parameters, and when dealing with millions of galaxies, such hand refinement of input parameters is an intractable task. Although large citizen science projects like Galaxy Zoo (Lintott et al. 2008) have been successful in processing many surveys in the past, even these will fail to keep up with the upcoming data glut. Moreover, reliable visual classifications require a decent signal-to-noise ratio, take time to set up and execute, and require an extremely careful de-biasing of the vote shares obtained (e.g., Lintott et al. 2008; Simmons et al. 2017).
From early attempts at using a CNN to classify galaxies morphologically (e.g., Dieleman et al. 2015) to the largest CNN produced morphology catalogs currently available (Cheng et al. 2021; Vega-Ferrero et al. 2021), most CNNs have provided broad, qualitative classifications, rather than numerical estimates of morphological parameters. Such studies typically entail classifying galaxies based on their morphological properties (e.g., based on whether the galaxy has a disk or a bulge or a bar, etc.) as opposed to predicting values of relevant morphological parameters that help characterize the galaxy (such as bulge-to-total-light ratio, radius, etc.). By contrast, Tuccillo et al. (2018) used a CNN to estimate the parameters of a single-component Sérsic fit, though without uncertainties. Meanwhile, the computation of full Bayesian posteriors for different morphological parameters is crucial for drawing scientific inferences that account for uncertainty and thus are indispensable in the derivation of robust scaling relations (e.g., Bernardi et al. 2013; van der Wel et al. 2014) or tests of theoretical models using morphology (e.g., Schawinski et al. 2014). Thus, producing posterior estimates will significantly increase the scientific potential of morphological catalogs produced using CNNs.
In this work, we introduce GaMPEN (the Galaxy Morphology Posterior Estimation Network), a novel machine-learning framework that estimates the Bayesian posteriors for three morphological parameters: the bulge-to-total-light ratio (LB /LT ), the effective radius (Re ), and the total flux (F). GaMPEN uses a CNN module to estimate the joint posterior probability distributions of these parameters. This is done by using the negative log-likelihood of the output parameters as the loss function combined with the Monte Carlo Dropout technique (Gal & Ghahramani 2016). We also used the full covariance matrix in the loss function, using a series of algebraic manipulations (see Section 4). The full covariance matrix accounts for dependencies among different output parameters and ensures that the posterior distributions for all three output variables are well calibrated.
Although the use of CNNs in the recent past has allowed astronomers to process large data volumes quickly, some challenges related to data preprocessing have remained. One of these challenges has to do with making cutouts of proper sizes. Most trained CNNs require input images of a fixed size—thus, most previous work (e.g., Cheng et al. 2021; Vega-Ferrero et al. 2021) has resorted to selecting a large cutout size for which most galaxies would remain in the frame. However, this means that for many galaxies in the data set, especially smaller ones, typical cutouts contain other galaxies in the frame, often leading to less accurate results. This problem is aggravated when designing a CNN applicable over an extensive range in redshift, which corresponds to a large range of galaxy sizes. Lastly, most previous work has used computations of Re from previous catalogs to estimate the correct cutout size to choose. This is, of course, not possible when one is trying to use a CNN on a new, unlabeled data set.
To address these challenges, GaMPEN automatically crops the input image frames using a spatial transformer network (STN) module upstream of the CNN. STNs are self-consistent modules that can be used for the spatial manipulation of data within machine-learning frameworks. In GaMPEN, based on the input image, the STN predicts the parameters of an affine transformation which is then applied to the input image. The transformed image is then passed onto the downstream CNN. The inclusion of the STN in the framework greatly reduces the amount of time spent on data preprocessing as it trains simultaneously with the downstream CNN without additional supervision. We later show in Section 3.1 how the STN automatically learns to make appropriate affine transformations (such as cropping) on the input data, which are helpful in the downstream task of morphological parameter estimation.
To the best of our knowledge, GaMPEN is the first machine-learning framework to apply an STN to optical imaging data and is the first to estimate full Bayesian posteriors for galaxy morphological parameters. In order to have a robust understanding of the performance, bias, and limitations of GaMPEN, we train and test GaMPEN on simulations of galaxy images—the only situation where we have access to the ground-truth morphological parameters of the galaxies. We match our simulations to the observations of the Hyper Suprime-Cam (HSC) Wide survey (Aihara et al. 2018), as this is an obvious application (to be described in a forthcoming paper). We use real HSC-Wide images, with their multiples galaxies, to validate the STN performance.
In Section 2, we describe the simulated data used to train and test GaMPEN. We describe the structure and code of GaMPEN in Section 3 and outline the entire mechanism behind the prediction of posteriors in Section 4. In Section 5, we describe GaMPEN's training procedure. We present our results in Section 6, and summarize our findings along with future applications of GaMPEN in Section 7. GaMPEN's data-access policies are described in Appendix A.
2. Simulated Galaxies
We train and test GaMPEN using mock galaxy image cutouts simulated to match g-band data from the HSC Subaru Strategic Program wide-field optical survey (Aihara et al. 2018). The Subaru Strategic Program, ongoing since 2014, uses the HSC prime-focus camera, which provides extremely high sensitivity and resolving power due to the large 8.2 m mirror of the Subaru Telescope. Its g-band seeing, with median FWHM of 0 85, is a large improvement over the Sloan Digital Sky Survey (SDSS; York et al. 2000), which has a median g-band seeing of 1
4.
To generate mock images, we used GalSim (Rowe et al. 2015), the modular galaxy image simulation toolkit. GalSim has been extensively tested and shown to yield very accurate rendered images of galaxies. We simulated 150,000 galaxies in total, with a mixture of both single and double components, in order to have a diverse training sample. To be exact, 75% of the simulated galaxies consisted of both bulge and disk components, while the remaining 25% had either a single disk or a bulge.
For both the bulge and disk components, we used the Sérsic profile, the surface brightness of which is given by
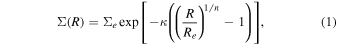
where Σe is the pixel surface brightness at the effective radius Re , n is the Seŕsic index, which controls the concentration of the light profile, and κ is a parameter coupled to n that ensures that half of the total flux is enclosed within Re . The standard formula for an exponential disk corresponds to n = 1, and a de Vaucouleurs profile is n = 4.
The parameters required to generate the Sérsic profiles were drawn from uniform distributions, over the ranges given in Table 1. For the disk and bulge components, we let the Sérsic index vary between 0.8–1.2 and 3.5–5.0, respectively. We chose to have varying Sérsic indices as opposed to fixed values for each component in order to have a training set with diverse light profiles. The parameter ranges for fluxes and half-light radii are quite expansive, such that the simulations represent most local galaxies (Binney & Merrifield 1998) at z ≤ 0.25 (i.e., the simulation parameters are chosen to match HSC z < 0.25 galaxies).
Table 1. Parameter Ranges of Simulated Galaxies
| Component Name | Sérsic Index | Half-light Radius | Flux | Axis Ratio | Position Angle |
|---|---|---|---|---|---|
| (arcsec) | (nJy) | (degrees) | |||
| Single-component Galaxies | |||||
| 0.8–1.2 or 3.5–5.0 a | 0.1–5.0 | 103 −5 × 106 | 0.25–1.0 | −90.0–90.0 | |
| Double-component Galaxies | |||||
| Disk | 0.8–1.2 | 0.1–5.0 | 0.0-1.0 b | 0.25–1.0 | −90.0–90.0 |
| Bulge | 3.5–5.0 | 0.1–3.0 | 1.0—Disk. Comp. b | 0.25–1.0 | Disk Comp. ± [0,15] c |
Notes. The above table shows the ranges of the various Sérsic profile parameters used to simulate training and testing data. 75% of the simulated galaxies have both disk and bulge components, and the remainder has either a disk or a bulge component. The distributions of all the simulation parameters are uniform except for the position angle and flux of the double-component galaxies. For more details about these choices, please refer to Section 2.
a The single-component galaxies are equally divided between galaxies with a Sérsic index between 0.8 and 1.2 and galaxies with a Sérsic index between 3.5 and 5.0. b Fractional fluxes are noted here. The bulge flux fraction is chosen such that for each simulated galaxy it is added with the disk flux fraction to give 1.0. The total flux of the galaxies is varied between 103 and 5 × 106 nJy. c The bulge position angle differs from the disk position angle by a randomly chosen value between −15° and +15°.Download table as: ASCIITypeset image
Specifically, single-component galaxies were assigned a half-light radius between 0.25 and 11.5 kpc. In the double-component galaxies, the disk half-light radius was varied across the same range, and the bulge half-light radius was varied between 0.25 and 7.0 kpc. To obtain the corresponding angular sizes for simulation, we placed the sample at z = 0.125 using the Planck18 cosmology (H0 = 67.7 km s−1 Mpc−1; Planck Collaboration et al. 2018) and the appropriate pixel scale.
For the single-component galaxies, the total flux was varied between 103 and 5 × 106 nJy (mAB ∼ 14–23). For the double-component galaxies, we first draw LB /LT from a uniform distribution between 0 and 1. Thereafter, the total flux of the galaxy is chosen from a uniform distribution with a range of 103−5 × 106 nJy. To assign fluxes to the bulge and disk components, we multiply LB /LT and (1 − LB /LT ), respectively, by the total flux. Not following this procedure and drawing the bulge and disk fluxes independently causes most galaxies in the training set to have a very high or a very low LB /LT , which is not the case for most galaxies, and in any case we already have single-component galaxies in our sample. For the double-component sample, we wanted to have a sufficient number of galaxies with intermediate values of LB /LT .
What matters in training a CNN is not matching the observed distributions of the simulation parameters; rather, it is spanning the full range of those parameters. Having too many of any one type—even if that is the reality in real data—can result in lower accuracy for minority populations (e.g., Ghosh et al. 2020). By not weighting the simulated galaxy sample in any specific regions of the parameter space, we are able to optimize GaMPEN for the full range of galaxy morphologies.
To make the two-dimensional light profiles generated by GalSim realistic, we convolved these with a representative point-spread function (PSF) and added appropriate noise. Figure 1 shows a randomly chosen simulated light profile, as well as the corresponding image cutout generated after PSF convolution and noise addition.
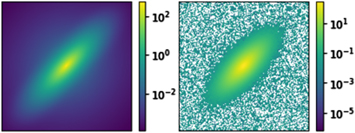
Figure 1. Two stages of simulating an HSC galaxy. (Left) A randomly chosen two-dimensional light profile generated by GalSim. (Right) The same image after PSF convolution and noise addition. The white pixels represent (small) negative values that arise from the process of noise addition.
Download figure:
Standard image High-resolution imageTo curate a collection of representative PSFs, we first selected 100 galaxies at random from the HSC PDR2 Wide field (Aihara et al. 2019) with z ≤ 0.25 and mg ≤ 23, and that did not have any quality flags set to True (the quality flags check for cosmic ray hits, interpolated pixels, etc.). We then used the HSC PSF Picker Tool 16 to obtain the PSF at the location of these 100 galaxies. Each simulated light profile was convolved with a randomly chosen PSF out of these 100. To make sure that the PSFs are representative (i.e., do not contain any outliers), we ran a test where we convolved each one with a simulated galaxy light profile, before adding noise. We then inspected all possible difference images for each convolved galaxy, to make sure the average pixel value of the difference image was always at least three orders of magnitude lower than the average pixel value of the convolved galaxy image.
To generate representative noise, we used one-thousand 2″ × 2″ sky objects from the HSC PDR2 Wide field. Sky objects are empty regions identified by the HSC pipeline that are outside object footprints and are recommended for being used in blank-sky measurements. We visually verified that our sky objects did not contain any sources. We then read in the pixel values of these sky objects to generate a large sample of noise pixels. We randomly sampled this collection of noise pixels to make two-dimensional arrays of the same size as that of the simulated images and then added them to the images.
All the simulated galaxy cutouts were chosen to have a size of 239 × 239 pixels, which translates to roughly 40″ × 40″ given HSC’s pixel scale of 0168 pixel−1. Ten randomly chosen simulated galaxies from our data set are shown in Figure 2.
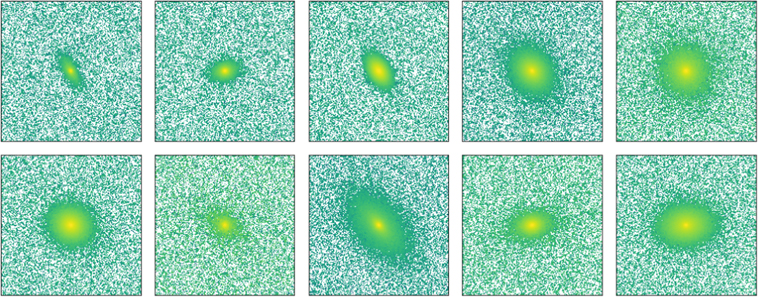
Figure 2. Ten randomly selected galaxies from our simulated data set. The simulation parameters are chosen such that the simulated galaxies represent a diverse range of light profiles and include most bright, local galaxies at z ≲ 0.25.
Download figure:
Standard image High-resolution image3. GaMPEN Architecture
Artificial neural networks, consisting of many connected individual units called artificial neurons, have been studied for more than five decades. These artificial neurons are usually arranged in multiple layers and such networks typically have (a) an input layer to feed data into the network; (b) an output layer that contains the result of propagating the data through the network. In between, there are additional hidden layer(s). Each neuron is characterized by a weight vector w = (w1, w2,…,wn ) and a bias b. The output of a single neuron in the network is given by
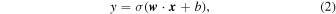
where σ is the chosen activation function of the neuron and x is the vector of inputs to the neuron. The process of training an artificial neural network involves finding the optimum set of weights and biases of all neurons such that, for a given set of inputs, the output of the network resembles the desired outputs as closely as possible. The optimization is usually performed by minimizing a loss function using stochastic gradient descent.
The backbone of GaMPEN is a CNN (Fukushima 1980; LeCun et al. 1998). Without convolutional layers, neural networks learn global patterns, whereas CNNs learn to identify thousands of local patterns in their input images that are translation invariant. Additionally, CNNs learn the spatial hierarchies of these patterns, allowing them to process increasingly complex and abstract visual concepts. These two key features have allowed deep CNNs to revolutionize the field of image processing in the last decade (Lecun et al. 2015; Schmidhuber 2015).
The architecture of GaMPEN is shown in Figure 3. It consists of an STN module followed by a downstream CNN module, described in Sections 3.1 and 3.2, respectively. The design of GaMPEN is based on our previously successful classification CNN, GaMorNet (Ghosh et al. 2020), as well as different variants of the Visual Geometry Group (VGG) networks (Simonyan & Zisserman 2014), which are highly effective at large-scale visual recognition. We tried different architectures of these base models by varying the depth of the entire network and the sizes of the various layers. To quickly and systematically search this model-design space, we use ModulosAI’s 17 AutoML platform, which uses a Bayesian optimization strategy. The said strategy involves using the current model’s performance to determine which variant to try next. When choosing new configurations, the optimizer balances the exploitation of well-performing search spaces and the exploration of unknown regions.
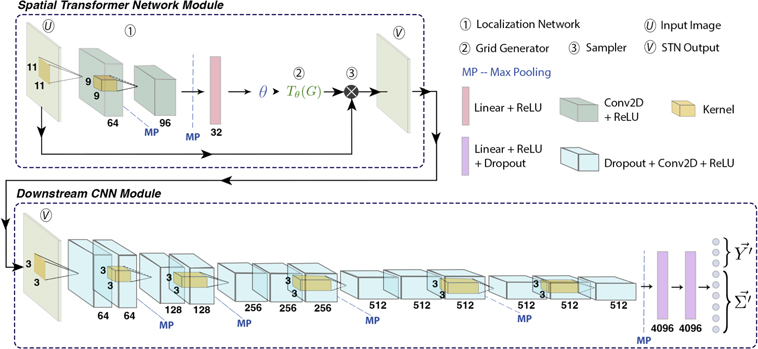
Figure 3. A schematic diagram of GaMPEN. GaMPEN’s architecture consists of a downstream CNN module preceded by an upstream STN module. The CNN module empowers GaMPEN to estimate posterior distributions of galaxy morphology parameters. The upstream STN module trains without any extra supervision and learns to apply appropriate cropping transformations to the input image before passing it on to the CNN (for more details about these modules, see Sections 3.1, 3.2). The numbers below each layer refer to the number of filters/neurons in each layer. The yellow boxes inside the convolutional layers show the kernel and the number beside it refers to the corresponding kernel size. Only one kernel is shown per set of convolutional layers; all other layers in the set have kernels of the same size. Conv2D and ReLU refer to Convolutional Layers and Rectified Linear Units, respectively (described in Section 3.2).
Download figure:
Standard image High-resolution imageTo implement GaMPEN, we use PyTorch, which is an open-source machine-learning framework, written in Python.
3.1. The Spatial Transformer Network Module
STNs were introduced by Jaderberg et al. (2015) as a learnable module that can be inserted in CNNs and explicitly allows for the spatial manipulation of data within the CNN. In the astronomical context, STNs have only been used by Wu et al. (2019) previously in morphological analysis of radio data.
In GaMPEN, the STN is upstream of the CNN, where it applies a two-dimensional affine transformation to the input image, and the transformed image is then passed to the CNN. Each input image is transformed differently by the STN, which learns the appropriate cropping during the training of the downstream CNN without additional supervision. As shown in the upper part of Figure 3, the STN consists of (1) a localization network, (2) a parameterized grid generator, and (3) a sampler, as described below.
The localization network takes the input image, U (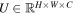 , with height H, width W, and C channels), and outputs
θ
, the six-parameter matrix of the affine transformation,
, with height H, width W, and C channels), and outputs
θ
, the six-parameter matrix of the affine transformation, 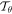 , to be applied to the input image. The localization network in the STN is a CNN with two convolutional layers followed by two fully connected layers at the end.
, to be applied to the input image. The localization network in the STN is a CNN with two convolutional layers followed by two fully connected layers at the end.
To perform the transformation, 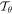 , the values of the output pixels are computed by applying a sampling kernel on the input image. As the first step in this process, the parameterized grid generator is used to generate a grid, G, of target coordinates,
, the values of the output pixels are computed by applying a sampling kernel on the input image. As the first step in this process, the parameterized grid generator is used to generate a grid, G, of target coordinates, 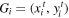 , forming the output of the STN. For our case,
, forming the output of the STN. For our case, 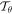 is a 2D affine transformation Aθ
, and the pointwise transformation is given by
is a 2D affine transformation Aθ
, and the pointwise transformation is given by
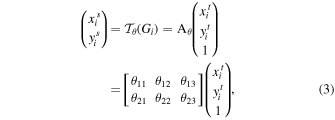
where 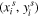 are the source coordinates in the input image that define the sample points (Jaderberg et al. 2015). The transformation shown in Equation (3) allows for cropping, translation, rotation, and skewing to be applied to the input image. However, the simulated galaxy images in our data set are already centered, and our primary aim of using the STN is to achieve optimal cropping; thus, we constrain the type of affine transformations allowed by modifying Aθ
such that
are the source coordinates in the input image that define the sample points (Jaderberg et al. 2015). The transformation shown in Equation (3) allows for cropping, translation, rotation, and skewing to be applied to the input image. However, the simulated galaxy images in our data set are already centered, and our primary aim of using the STN is to achieve optimal cropping; thus, we constrain the type of affine transformations allowed by modifying Aθ
such that
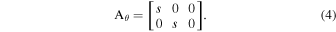
The localization network predicts the optimal value of s for each input image. As can be seen from Equation (4), s = 1 results in an identity transformation (i.e., the image output by the STN and the input image are the same). For values of s < 1, lower fractions of the input image are retained in the output image. For example, when s = 0.7, 70% of each side (length/width) of the input image is retained in the output image.
Note that although GaMPEN's STN does not perform rotations, we are able to induce rotational invariance using our training procedure. Since our simulated training set is very large, it happens to be that there are many galaxies with different position angles, but similar (other) structural parameters.
In the final step, the sampler takes the set of sampling points 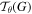 along with the input image, U, to produce the output image, V. Each
along with the input image, U, to produce the output image, V. Each 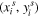 coordinate in
coordinate in 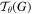 defines the spatial location in the input where a bilinear sampling kernel is applied to get the value at a particular pixel in the output image. This can be written as
defines the spatial location in the input where a bilinear sampling kernel is applied to get the value at a particular pixel in the output image. This can be written as
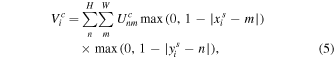
where 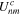 is the value at location (n,m) in channel c of the input, and Vi
c
is the output value for pixel i at location
is the value at location (n,m) in channel c of the input, and Vi
c
is the output value for pixel i at location 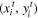 in channel c. To allow the backpropagation of the loss through this sampling mechanism, we can define the gradients with respect to U and G. This allows loss gradients to flow back to the sampling grid coordinates and therefore back to the transformation parameter s and the localization network.
in channel c. To allow the backpropagation of the loss through this sampling mechanism, we can define the gradients with respect to U and G. This allows loss gradients to flow back to the sampling grid coordinates and therefore back to the transformation parameter s and the localization network.
Placing the STN upstream in the GaMPEN framework allows the network to learn how to actively transform the input image to minimize the overall loss function during training. Because the transformation we use is differentiable with respect to the parameters, gradients can be backpropagated through the sampling points  to the localization network output
θ
. This crucial property allows the STN to be trained using standard backpropagation along with the downstream CNN, without any additional supervision.
to the localization network output
θ
. This crucial property allows the STN to be trained using standard backpropagation along with the downstream CNN, without any additional supervision.
Figure 4 shows examples of the transformations applied by the STN of a trained GaMPEN framework to simulated HSC data. As can be seen, the STN learns to apply an optimal amount of cropping for each input galaxy.
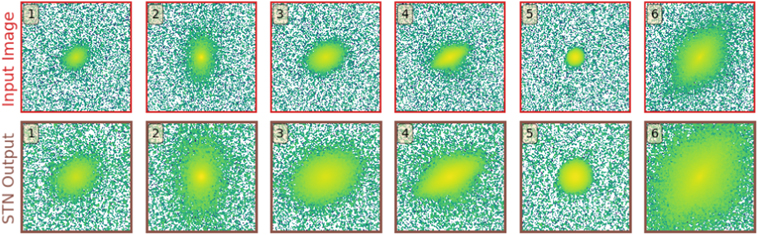
Figure 4. Examples of the transformation applied by the STN to six randomly selected input galaxy images. The top row shows the input galaxy images, and the bottom row shows the corresponding output from the STN. The numbers in the top-left yellow boxes help correspond the output images to the input images. As can be seen, the STN learns to apply an optimal amount of cropping for each input galaxy.
Download figure:
Standard image High-resolution imageTo further validate the performance of our STN, we process all images in our testing data set through the STN module of a trained GaMPEN framework. After that, we sort all the processed images using the value of the parameter s (from Equation (4)) predicted by the localization network. Higher values of s denote that a more significant fraction of the input image was retained in the output image produced by the STN (i.e., minimal cropping). In Figure 5, we show the images from our testing data set with the highest and lowest values of s. Figure 5 demonstrates that the STN correctly learns to apply the most aggressive crops to smallest galaxies in our data set, and the least aggressive crops to the largest galaxies.
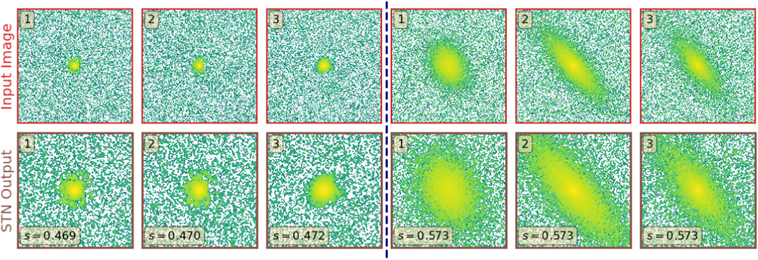
Figure 5. (Left) Galaxies in the testing data set with the lowest values of s (i.e., the most aggressive crops) (Right) Galaxies in the testing data set with the highest values of s (i.e., the least aggressive crops). As can be seen, the STN correctly learns to apply the most aggressive crops to small galaxies; and the least aggressive crops to large galaxies.
Download figure:
Standard image High-resolution imageLastly, in order to demonstrate the purpose of including an STN in GaMPEN, we show its performance on real HSC galaxies. We apply the STN module of a trained GaMPEN framework to three randomly chosen g-band galaxies in the HSC-Wide survey with z ≤ 0.25 and mg ≤ 23. Each input image is 40″ × 40″. (Note that, for this demonstration, we did not retrain GaMPEN on real galaxies in any way.) The results are shown in Figure 6. The STN learns to systematically crop out secondary galaxies in the cutouts and focus on the galaxy of interest at the center of the cutout. At the same time, the STN also correctly applies minimal cropping to the largest galaxies, making sure the entirety of these galaxies remains in the frame.
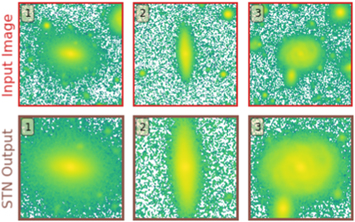
Figure 6. Examples of the transformation applied by a trained STN to real HSC-Wide g-band galaxies. The STN helps the downstream CNN to focus on the galaxy of interest at the center of the cutout by cropping out most secondary galaxies present in the input frame.
Download figure:
Standard image High-resolution image3.2. The Convolutional Neural Network Module
The input image, once transformed by the STN, is passed to the downstream CNN module, as depicted in Figure 3. This downstream module predicts the posterior distribution of the bulge-to-total-light ratio, effective radius, and total flux for each input galaxy.
The architecture of this downstream CNN is based on the design of VGG-16 (Simonyan & Zisserman 2014), a CNN that performed well in the 2014 ImageNet Large Scale Visual Recognition Challenge, wherein different teams compete to classify about 14 million hand-annotated images. The primary feature of the VGG class of networks is that they use tiny convolutional filters combined with significantly deep networks, which have been shown to be highly successful in computer vision. Broadly speaking, GaMPEN's downstream CNN consists of 13 convolutional layers, followed by three fully connected layers. The convolutional layers are arranged in five blocks, and in between each block is a max-pooling layer. Note that one of the primary differences between our network and VGG-16 is that all the convolutional layers in GaMPEN are preceded by a dropout layer in order to facilitate the prediction of epistemic uncertainties, as described further in Section 4.1.
The convolutional layers (Conv2D in Figure 3) work in unison to identify hierarchies of translational invariant spatial patterns in the images. Each convolutional layer does this by using a collection of 3 × 3 pixel windows (called filters), wherein each filter is a specific pattern that the CNN is looking for in the image. These windows slide around the input to generate a response-map or feature-map, which quantifies the presence of the filter’s pattern at different locations of the input. Each convolutional layer is preceded by a dropout layer, which is one of the most effective and commonly used regularization techniques that prevent overfitting by randomly dropping (i.e., setting to zero) several output features of the layer during training. The dropout rate defines the fraction of features that are zeroed out. For GaMPEN, our choice of the dropout rate is guided by calibration of the predicted uncertainties and is described in Section 5.
The goal of the max-pooling layers (MP in Figure 3) is to aggressively downsample the outputs of the convolutional layer that they follow. Simply speaking, max pooling is dividing the output of the convolutional layer into a collection of windows and then using the maximum value in each window as the output. Max pooling can be thought of as a technique for detecting a given feature in a broad region of the image and then throwing away the exact positional information. The intuition is that once a feature has been found, its exact location is not as crucial as its rough location relative to other features. An additional advantage is that by aggressively downsampling, max pooling forces successive convolutional layers to look at increasingly large windows as a fraction of the input to the layer. This helps to induce spatial-filter hierarchies.
Throughout the network, we use the rectified linear unit (ReLU in Figure 3) as the activation function, except for the output layer, which is linear. The output of a ReLU unit with input
x
, weight
w
, and bias b is given by 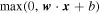 . The application of the ReLU activation function makes the network non-linear.
. The application of the ReLU activation function makes the network non-linear.
At the end of the network are three fully connected layers. They use the output of the convolutional layers, denoting the presence of various features in the image, to predict the correct output variables given an image. The output layer predicts nine parameters. Three of these construct the vector of means of the output variables 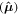 , and the remaining six are used to construct the covariance matrix
, and the remaining six are used to construct the covariance matrix 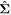 . In Section 4, we describe more about how these two variables are used to generate the predicted distributions.
. In Section 4, we describe more about how these two variables are used to generate the predicted distributions.
Table 3 in Appendix C gives extended descriptions of each GaMPEN layer. For more technical details about the various layers and functions described there, we refer the reader to Nielsen (2015), Goodfellow et al. (2016), and Chollet (2021).
4. Prediction of Posteriors
Traditional CNNs consist of neurons with fixed, deterministic values of weights and biases, resulting in deterministic outputs. However, if the weights in such a network are probability distributions, then the calculation can be defined within a Bayesian framework (Denker & Lecun 1990). Such CNNs can then be used to capture the posterior probabilities of the outputs, resulting in well-defined estimates of uncertainties. The key distinguishing property of the Bayesian approach is marginalization over multiple networks rather than a single optimization run.
Two primary sources of error contribute to the uncertainties in the parameters predicted by GaMPEN. The first arises from errors inherent to the input imaging data (e.g., noise and PSF blurring), and this is commonly referred to as aleatoric uncertainty. The second error comes from the limitations of the model being used for prediction (e.g., the number of free parameters in GaMPEN, the amount of training data, etc.); this is referred to as epistemic uncertainty. It is important to note that while epistemic uncertainties can be reduced with proper changes to the model (e.g., more training data, more flexible model), aleatoric uncertainties are determined by the input images and thus cannot be reduced. There has been much recent work on how to estimate uncertainties efficiently in deep learning (e.g., Gal & Ghahramani 2016; Kendall & Gal 2017; Pawlowski et al. 2017; Wilson & Izmailov 2020) and some of these techniques have also been applied to astrophysical problems (e.g., Perreault Levasseur et al. 2017; Walmsley et al. 2020; Cranmer et al. 2021; Wagner-Carena et al. 2021). The following two sections describe how we arrange for GaMPEN to estimate both parameter values and their uncertainties.
4.1. Bayesian Implementation of GaMPEN and Epistemic Uncertainties
To create a Bayesian framework while predicting morphological parameters, we have to treat the model itself as a random variable—or more precisely, the weights of our network must be probabilistic distributions instead of single values. For a network with weights, ω, and a training data set, 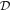 , of size N with input images
, of size N with input images 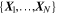 and output parameters
and output parameters 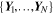 , the posterior of the network weights,
, the posterior of the network weights, 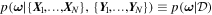 represents the plausible network parameters. To predict the probability distribution of the output variable
represents the plausible network parameters. To predict the probability distribution of the output variable 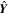 given a new test image
given a new test image 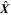 , we need to marginalize over all possible weights ω:
, we need to marginalize over all possible weights ω:
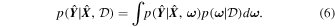
In order to calculate the above integral, we need to know 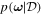 , i.e., how likely is a particular set of weights given the available training data,
, i.e., how likely is a particular set of weights given the available training data, 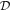 . Since we have trained only the one model, it does not tell us how likely different sets of weights are. Different approximations have been introduced in order to calculate this distribution, with variational inference (Jordan et al. 1999) being the most popular.
. Since we have trained only the one model, it does not tell us how likely different sets of weights are. Different approximations have been introduced in order to calculate this distribution, with variational inference (Jordan et al. 1999) being the most popular.
Now, the dropout technique was introduced by Srivastava et al. (2014) in order to prevent neural networks from overfitting; they temporarily removed random neurons from the network according to a Bernoulli distribution, i.e., individual nodes were set to zero with a probability, p, known as the dropout rate. This dropout process can also be interpreted as taking the trained model and permuting it into a different one (Srivastava et al. 2014).
Using variational inference and dropout, we can approximate the integral in Equation (6) as
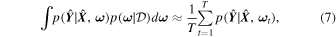
wherein we perform T forward passes with dropout enabled and ω t is the set of weights during the tth forward pass. This procedure is what is referred to as Monte Carlo dropout. For a detailed derivation of Equation (7), please refer to Appendix B.
In order to obtain epistemic uncertainties for GaMPEN, we insert a dropout layer before every weight layer in the network. Each forward pass through GaMPEN samples the approximate parameter posterior. Thus, in order to obtain epistemic uncertainties, we feed every test image 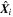 to the trained GaMPEN framework T times and collect the outputs. In implementing the Monte Carlo Dropout technique, an often-ignored key step is tuning the dropout rate (i.e., the rate at which neurons are set to zero). We discuss the tuning of the dropout rate for GaMPEN in Section 5.
to the trained GaMPEN framework T times and collect the outputs. In implementing the Monte Carlo Dropout technique, an often-ignored key step is tuning the dropout rate (i.e., the rate at which neurons are set to zero). We discuss the tuning of the dropout rate for GaMPEN in Section 5.
4.2. Likelihood Calculation and Aleatoric Uncertainties
Our simulated training data consists of noisy input images by design, but we know the corresponding morphological parameters with perfect accuracy. However, due to the different amounts of noise in each image, the predictions of GaMPEN at test time should have different levels of uncertainties. Thus, in this situation, we want to use a heteroscedastic model—a model that can capture different levels of uncertainties in its output predictions. We achieve this by training GaMPEN to predict the aleatoric uncertainties.
As outlined in Section 5, GaMPEN predicts a multivariate log-normal distribution of output variables for any given input image. Thus, for a given set of network weights
ω
, the likelihood 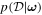 is simply the product of the probabilities that the GaMPEN output for each image is drawn from the associated multivariate Gaussian distribution
is simply the product of the probabilities that the GaMPEN output for each image is drawn from the associated multivariate Gaussian distribution 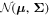 in
R
3, with mean
μ
and covariance matrix Σ.
in
R
3, with mean
μ
and covariance matrix Σ.
Although we would like to use GaMPEN to predict aleatoric uncertainties, the covariance matrix, Σ, is not known a priori. Instead, we train GaMPEN to learn these values by minimizing the negative log-likelihood of the output parameters for the training set, which can be written as
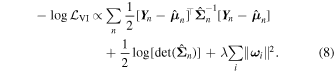
where 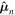 and
and 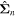 are the mean and covariance matrix of the multivariate Gaussian distribution predicted by GaMPEN for an image,
X
n
. λ is the strength of the regularization term, and
ω
i
are sampled from q(
ω
). For a detailed derivation of Equation (8), we refer the interested reader to Appendix C.
are the mean and covariance matrix of the multivariate Gaussian distribution predicted by GaMPEN for an image,
X
n
. λ is the strength of the regularization term, and
ω
i
are sampled from q(
ω
). For a detailed derivation of Equation (8), we refer the interested reader to Appendix C.
The covariance matrix here represents the uncertainties in the predicted parameters arising from inherent corruptions to the input or the output data. Note that using the full covariance matrix in Equation (8) instead of just the diagonal terms (i.e., assuming the output variables to be independent), helps GaMPEN to incorporate the structured relationship between the different output parameters. We further outline the effects of this in Section 5.
4.3. Practical Implementation Details
In order to predict μ and Σ, the final layer of GaMPEN contains nine output nodes (see Figure 3). Three of these nodes are used to characterize μ . Now, although Σ is a 3 × 3 matrix, we are able to characterize it with just six parameters due to its special properties. Because Σ is a symmetric, positive-definite matrix, we can use the LDL decomposition, a variant of the Cholesky decomposition (Cholesky 1924), to represent
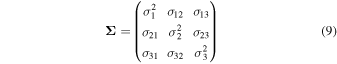
as Σ = L D L ⊤, where
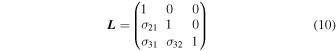
and
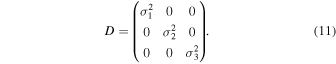
Thus, three of GaMPEN's output nodes are used to predict the off-diagonal elements in Equation (10), and three more are used to predict 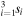 where
where 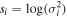 . We predict si
instead of
. We predict si
instead of 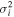 in order to achieve better numerical stability during training.
in order to achieve better numerical stability during training.
The loss function, outlined in Equation (8), contains the determinant and the inverse of Σ. Calculation of the determinant and the inverse of a matrix are potentially numerically unstable and slow operations. Thus, in order to achieve the maximum speed possible on our GPUs and for numerical stability, we replace these operations using the Cholesky decomposition outlined above and standard linear algebra. That is, Σ−1 can be written as 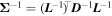 , where
, where

because D is a diagonal matrix. Because L is a lower triangular matrix, we can also write its inverse as
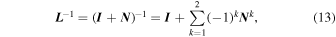
where I is a 3 × 3 identity matrix and N is a strictly lower triangular and nilpotent matrix such that N = L − I .
Finally, we can write the 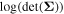 as
as

By combining Equations (12)–(14), we can calculate the log-likelihood outlined in Equation (8) without having to calculate the inverse or determinant of any matrix, allowing us to fully utilize the capabilities of a GPU and avoiding any numerical instabilities.
4.4. Combining Aleatoric and Epistemic Uncertainties
To obtain the posterior distribution of the output variables, we need to combine the aleatoric and epistemic uncertainties. After training a model by maximizing the log-likelihood outlined in Equation (8), we perform Monte Carlo dropout. To do this, as outlined in Figure 7, we feed each input image, 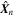 , in the test set 1000 times into GaMPEN with dropout enabled. During each iteration, we collect the predicted set of
, in the test set 1000 times into GaMPEN with dropout enabled. During each iteration, we collect the predicted set of 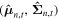 for the tth forward pass. Then, for each forward pass, we draw a sample
for the tth forward pass. Then, for each forward pass, we draw a sample 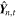 from the multivariate normal distribution
from the multivariate normal distribution 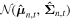 .
.
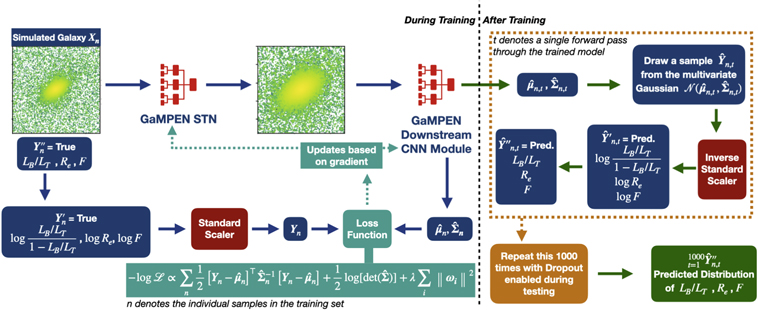
Figure 7. Diagram outlining the training (left) and inference (right) phases of the GaMPEN workflow. Training consists of feeding 105,000 simulated images (with known parameter values) through the STN and CNN modules, minimizing the loss function (Equation (8)) using stochastic gradient descent. During this process, we rescale the variables as described in the text, and return them to the original variable space during inference. After the STN+CNN are trained, the inference step consists of 1000 forward passes with dropout enabled for each galaxy image. We draw a sample from the predicted multivariate Gaussian distribution during each forward pass, and the collection of these samples gives us the predicted posterior distribution.
Download figure:
Standard image High-resolution imageThe distribution generated by the collection of all 1000 forward passes, 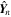 , represents the predicted posterior distribution for the test image
, represents the predicted posterior distribution for the test image 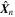 . The different forward passes capture the epistemic uncertainties, and each prediction in this sample also has its associated aleatoric uncertainty represented by
. The different forward passes capture the epistemic uncertainties, and each prediction in this sample also has its associated aleatoric uncertainty represented by 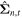 . Thus the above procedure allows us to incorporate both aleatoric and epistemic uncertainties in the prediction of posteriors of morphological parameters by GaMPEN.
. Thus the above procedure allows us to incorporate both aleatoric and epistemic uncertainties in the prediction of posteriors of morphological parameters by GaMPEN.
5. Training GaMPEN
We split the data set of 150,000 simulated galaxies into training, validation, and testing sets with 70%, 15%, and 15% of the total sample, respectively. We train GaMPEN using the training set, and set the values of various hyperparameters (e.g., learning rate, batch size; see below) using the validation set. Finally, we evaluate the trained model on the testing set (which has never been seen before by the network) and report the results in Section 6.
We pass all the images in the simulated data set through the arsinh function to reduce the dynamic range of pixel values in the images. This function behaves linearly around zero and logarithmically for large values. Reducing the dynamic range of pixel values has been found to be helpful in neural network convergence (e.g., Walmsley et al. 2021; Zanisi et al. 2021; Tanaka et al. 2022), hence this approach.
The three output variables that we predict with GaMPEN have quite different ranges, by orders of magnitude. Thus, we rescale these ground-truth training values before feeding them into the network in order to prevent variables with larger numerical values from making a disproportionate contribution to the loss function. Additionally, we also need to make sure that none of the values predicted by GaMPEN happen to be unphysical; that is, we require all output values to adhere to the following ranges: 0 ≤ LB /LT ≤ 1; Re > 0; F > 0.
Therefore, we first apply the logit transformation to LB /LT and log transformations to Re and F:
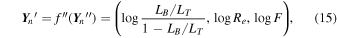
where Y n ″ = [LB /LT , Re , F] is the set of ground-truth parameters corresponding to the simulated image, X n , and f″ is how we refer to the transformation in Equation (15). Note that the uniformity of these transformations allows us to write the likelihood in terms of a multivariate Gaussian distribution. Next, we apply the standard scaler to each parameter (calibrated on the training data), which amounts to subtracting the mean value of each parameter and scaling its variance to unity:
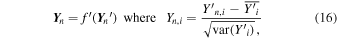
where the i subscript refers to each of the three parameters. Combining the above transformations, 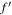 and f″, ensures that all three variables have similar numerical ranges.
and f″, ensures that all three variables have similar numerical ranges.
Note that effectively GaMPEN is trained in the
Y
n
variable space, and the predictions made by GaMPEN are also in this space. Thus, post training, during inference, we need to apply the inverse of the standard scaler function, 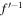 (with no retuning of the mean or variance), followed by the inverse of the logit and log transformations, f″−1, as indicated in Figure 7. These final transformations also ensure that the predicted values are all within the physical ranges mentioned earlier.
(with no retuning of the mean or variance), followed by the inverse of the logit and log transformations, f″−1, as indicated in Figure 7. These final transformations also ensure that the predicted values are all within the physical ranges mentioned earlier.
We train GaMPEN by minimizing the loss function in Equation (8) using stochastic gradient descent, wherein we estimate the gradient of the loss function using a mini-batch of training samples and update the network weights and biases accordingly. Calculation of the gradient is done using the backpropagation algorithm, and we refer the interested reader to Rumelhart et al. (1986) for details.
The training process involves hyperparameters that must be chosen: the learning rate (the step size during gradient descent), momentum (acceleration factor used for faster convergence), strength of L2 regularization (λ in the loss function in Equation (8)), and batch size (the number of images processed before weights and biases are updated). To choose these hyperparameters, we trained GaMPEN with a given set of hyperparameters for 40 epochs, then verified convergence by checking whether the value of the loss function and the mean-absolute error on the validation set had stabilized over at least the last 10 epochs. An epoch of training refers to running all of the images in the training set through the network once. We chose final hyperparameters that resulted in the lowest value for the loss function. This resulted in the following values: learning rate 5 × 10−7; momentum 0.99; strength of L2 regularization λ = 10−4; and batch size 16. The grid of values we used for the hyperparameter search is as follows: learning rate 10−5, 5 × 10−5, 10−6, 5 × 10−6, …, 5 × 10−8; momentum 0.8, 0.9, 0.95, 0.99; λ, 10−5,10−4, …, 10−2; and batch size 8, 16, 32, 64.
One of the most critical adjustable parameters is the dropout rate, as it directly affects the calculation of the epistemic uncertainties (as described in Section 4.1). On average, higher dropout rates lead networks to estimate higher epistemic uncertainties. To determine the optimal value for the dropout rate, we trained variants of GaMPEN with dropout rates from 0–0.2, all with the same optimized values of momentum, learning rate, and batch size given above. After that, we performed inference using each model as outlined in Figure 7.
To compare these models, we calculated the percentile coverage probabilities associated with each model, defined as the percentage of the total test examples where the true value of the parameter lies within a particular confidence interval of the predicted distribution. We calculate the coverage probabilities associated with the 68.27%, 95.45%, and 99.73% central percentile confidence levels, corresponding to the 1σ, 2σ, and 3σ confidence levels for a normal distribution. For each distribution predicted by GaMPEN, we define the 68.27% confidence interval as the region on the x-axis of the distribution that contains 68.27% of the most probable values of the integrated probability distribution. In order to estimate the probability distribution function from the GaMPEN predictions (which are discrete), we use kernel density estimation, which is a non-parametric technique to estimate the probability density function of a random variable.
We calculate the 95.45% and 99.73% confidence intervals of the predicted distributions in the same fashion. Finally, we calculate the percentage of test examples for which the true parameter values lie within each of these confidence intervals. An accurate and unbiased estimator should produce coverage probabilities equal to the confidence interval for which it was calculated (e.g., the coverage probability corresponding to the 68.27% confidence interval should be 68.27%).
Figure 8 shows the coverage probabilities for the three output parameters individually (top three panels), as well as the coverage probabilities averaged over the three output variables (bottom panel). As can be seen, higher values of the dropout rate lead to GaMPEN overpredicting the epistemic uncertainties, resulting in too high coverage probabilities. In contrast, extremely low values lead to GaMPEN underpredicting the epistemic uncertainties. For a dropout rate of 7 × 10−4, the calculated coverage probabilities are very close to their corresponding confidence levels, resulting in accurately calibrated posteriors. The dropout rate is clearly a variational parameter of GaMPEN, and all the results shown hereafter correspond to a GaMPEN model trained with a dropout rate of 7 × 10−4.
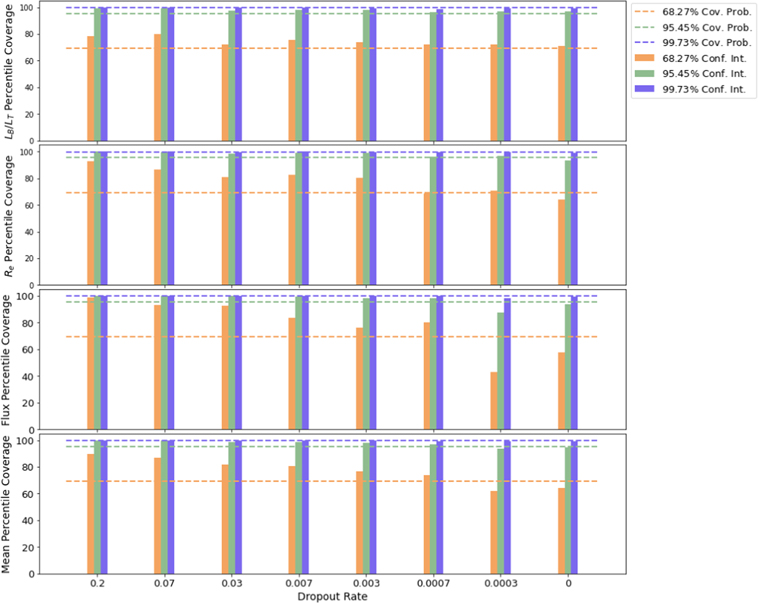
Figure 8. The calculated percentile coverage probabilities for different dropout rates. The top three rows show coverage probabilities for each output variable individually, while the bottom row shows the probabilities averaged over the three variables. The coverage probabilities are defined as the percentage of the total test examples where the true value of the parameter lies within a particular confidence interval of the predicted distribution. A dropout rate of 7 × 10−4 leads to coverage probabilities very close to their corresponding confidence levels.
Download figure:
Standard image High-resolution imageIt is important to note that the inclusion of the full covariance matrix in the loss function allowed us to incorporate the relationships between the different output variables in GaMPEN predictions. This allowed us to achieve simultaneous calibration of the coverage probabilities for all three output variables. In contrast, using only the diagonal elements of the covariance matrix resulted in substantial disagreement, for a fixed dropout rate, among the coverage probabilities of the different parameters. Additionally, when we used three different neural networks to predict each output variable, we achieved a poorer overall accuracy. Thus, using the full covariance matrix, facilitated by the linear algebraic tricks outlined in Section 4.3, allows GaMPEN to predict accurate, calibrated posteriors.
6. Results
After training GaMPEN and tuning its hyperparameters on the training and validation sets, as outlined in Section 5, we perform inference using the testing set of 22,500 galaxies.
6.1. Inspecting the Predicted Posteriors
As outlined in Figure 7 and Section 4.4, during the inference phase, we pass each image in the testing set 1000 times through GaMPEN. Note that due to our use of Monte Carlo dropout, each of these forward passes happens through a slightly different network because of how the technique drops out (sets to zero) randomly selected neurons according to a Bernoulli distribution. This technique allows us to effectively factor in the uncertainty about our predictive model into GaMPEN predictions. For each forward pass t and for each test image 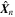 , GaMPEN predicts a vector of means
, GaMPEN predicts a vector of means 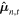 and a covariance matrix
and a covariance matrix 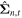 . These two parameters are used to define a multivariate Gaussian distribution
. These two parameters are used to define a multivariate Gaussian distribution 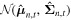 from which we draw a sample
from which we draw a sample 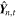 . These are then processed through two sets of transformations (
. These are then processed through two sets of transformations (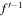 and f″−1) outlined in Section 5 resulting in the transformed prediction
and f″−1) outlined in Section 5 resulting in the transformed prediction 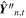 . The collection of these samples for the 1000 forward passes
. The collection of these samples for the 1000 forward passes 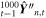 represents the posterior distribution predicted by GaMPEN for the test image
represents the posterior distribution predicted by GaMPEN for the test image 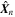 .
.
Using the above process, we extract the joint probability distribution of all the output parameters for each of the 22,500 galaxies in our test set. Figure 9 shows the two-dimensional joint distributions of the output parameters, as well the marginalized distributions, for a randomly chosen galaxy in our test set. The same galaxy is shown in the second row of Figure 10, which illustrates the predicted posterior distributions for a few more cases. Figure 10 also shows the image of each galaxy on the left. As expected, all the predicted distributions are unimodal, smooth, and resemble Gaussian or truncated Gaussian distributions. For each predicted distribution, the figure also shows the parameter space regions that contain 68.27%, 95.45%, and 99.73% of the most probable values of the integrated probability distribution. We use kernel density estimation to estimate the probability distribution function (PDF; shown by a blue line in the figure) from the predicted values. The mode of this PDF is what we refer to as the predicted value when calculating residuals. In the figure, for most cases, the true value lies within the most probable 68.27% percentile region. We also visually inspected the distributions predicted by GaMPEN for ∼200 galaxies to ensure that there were no systematic or catastrophic errors (e.g., substantial errors for a specific parameter only, or bimodal or irregular distributions for specific kinds of galaxies, etc.).
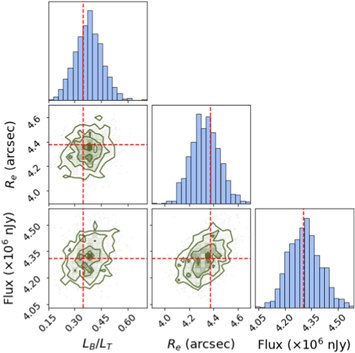
Figure 9. Joint and marginalized probability distributions predicted by GaMPEN for a randomly chosen galaxy in our testing set. The red dotted lines show the true values of the parameters.
Download figure:
Standard image High-resolution image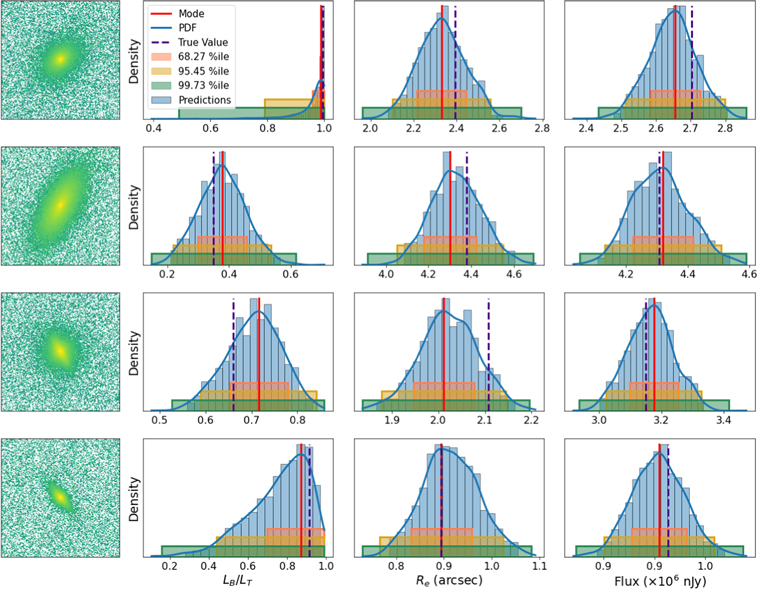
Figure 10. Examples of predicted posterior distributions for four randomly chosen simulated galaxies. The blue shaded histogram shows the predictions from GaMPEN and the blue solid lines show the associated probability distribution functions estimated by kernel density estimation. These are used to calculate the confidence intervals shown in the figure with pink, yellow, and green shading. The mode (red line) shows the most probable value of each morphological parameter. As expected, in most cases, the true value (purple line) lies within the 68.27% confidence interval.
Download figure:
Standard image High-resolution imageBy design, GaMPEN predicts only physically possible values. This is especially apparent in the LB /LT column of rows 1 and 4 of Figure 10. Note that to achieve this, we do not artificially truncate these distributions. Instead, we use the inverse of the logit transformation on the prediction space of GaMPEN as outlined in Section 5. This ensures that the predicted LB /LT values are always between 0 and 1. Similarly, we also ensure that the Re and F values predicted by GaMPEN are positive through appropriate transformations.
6.2. Evaluating the Accuracy of GaMPEN
In Section 6.1, we explored the predicted distributions for a handful of cases, where the true values of the parameters mostly lay within the densest parts of the probability distribution predicted by GaMPEN. In order to evaluate the accuracy of GaMPEN, we now report summary statistics that outline the framework’s performance on the entire testing set.
In Table 2, we report the coverage probabilities that GaMPEN achieves on the test set. In the ideal situation, they would perfectly mirror the confidence levels; that is, 68.27% of the time, the true value would lie within 68.27% of the most probable volume of the predicted distribution. (Note that in Section 5 we tuned the dropout rate so they coincide over the validation set, whereas Table 2 is calculated on the testing set). Clearly, GaMPEN produces well-calibrated and accurate posteriors, consistently close to the claimed confidence levels. Additionally, we note that even for the flux, for which the coverage probabilities are most discrepant, the uncertainties predicted by GaMPEN are in any case overestimates (i.e., conservative). If GaMPEN were used in a scenario that requires perfect alignment of coverage probabilities, users could employ techniques such as importance sampling (Kloek & van Dijk 1978) on the distributions predicted by GaMPEN.
Table 2. Coverage Probabilities on the Test Set
| Parameter | 68.27% | 95.45% | 99.73% |
|---|---|---|---|
| Name | Conf. Level | Conf. Level | Conf. Level |
| LB /LT | 71.8% | 96.9% | 98.9% |
| Re | 68.1% | 95.9% | 98.3% |
| F | 78.7% | 98.2% | 99.9% |
| Mean | 72.9% | 97.0% | 99.0% |
Note. The coverage probabilities are defined as the percentage of the total test samples where the true value of the parameter lies within a particular confidence interval of the predicted distribution.
Download table as: ASCIITypeset image
Having defined the overall percentage of cases where the true values are within particular confidence levels of the predicted distributions, we now quantify the difference between the most probable values of the predicted parameters (i.e., modes of these predicted distributions) and the true values.
Figure 11 shows the most probable values predicted by GaMPEN for the testing set versus the true values, in hexagonal bins of roughly equal size, with the number of galaxies represented according to the color bar on the right. We have used a logarithmic color bar to visualize even small clusters of galaxies in this plane. Most galaxies are clustered around the line of equality, showing that the most probable values of the distributions predicted by GaMPEN closely track the true values of the parameters.
Figure 11. The true values of the galaxy parameters plotted against the most probable values predicted by GaMPEN. The black dashed line marks the y = x diagonal on which perfectly recovered parameters should lie. The color of each hexagon corresponds to the number of galaxies it contains, as indicated by the color bar at right.
Download figure:
Standard image High-resolution imageThe middle panel of Figure 11 shows a small bias (note that the color scale is logarithmic) toward low predictions of Re , especially for true Re > 4″. Features like this have been seen before in other machine-learning studies and are typically referred to as an edge effect—that is, sometimes the model performs poorly at the edges of the parameter space on which it was trained. Here, since Re = 5″ is the largest radius present in our training data, for some galaxies with Re close to 5″, the network is hesitant to predict the highest value it has ever seen and predicts a slightly lower value. This results in the small bias toward lower predicted values of Re . However, note that despite this effect for a small number of galaxies; even at a large radius, GaMPEN accurately estimates Re for the large majority of galaxies. Among some other larger deviations evident in Figure 11, are predictions near the limits of LB /LT . We explore this further below.
In Figure 12, we show the residual distribution for the three parameters predicted by GaMPEN. We define the residual for each parameter as the difference between the most probable predicted value and the true value, i.e., 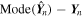 . The box in the upper left corner gives the mean (μ), median (
. The box in the upper left corner gives the mean (μ), median (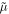 ), and standard deviation (σ) of each residual distribution. All three distributions are normally distributed (verified using the Shapiro–Wilk test), and have
), and standard deviation (σ) of each residual distribution. All three distributions are normally distributed (verified using the Shapiro–Wilk test), and have 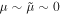 . The GaMPEN prediction of the bulge-to-total-light ratio is, in ∼68.27% of cases, within 0.1 of the true value. The typical error in effective radius is 0
. The GaMPEN prediction of the bulge-to-total-light ratio is, in ∼68.27% of cases, within 0.1 of the true value. The typical error in effective radius is 017. Typical uncertainties in the flux are at the 0.1%–1% level.
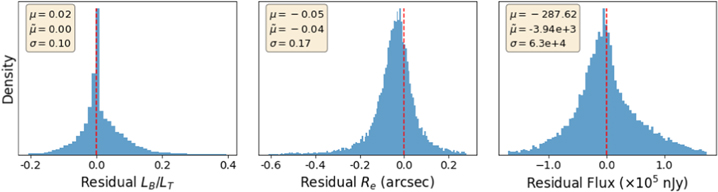
Figure 12. Histograms of residuals for all galaxies in the testing set. We define the residuals as the difference between the true value and the most probable value predicted by GaMPEN. The dashed vertical line represents x = 0, denoting cases with perfectly recovered parameter values. The mean (μ), median (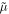 ), and standard deviation (σ) of each residual distribution are listed in each panel.
), and standard deviation (σ) of each residual distribution are listed in each panel.
Download figure:
Standard image High-resolution imageAlthough Figures 11 and 12 indicate the overall accuracy of GaMPEN, they do not reveal how those errors depend on location in the parameter space. This is critical information as this enables us to potentially ignore predictions for regions of parameter space that have large errors (according to the validation set). Figure 13 shows the residuals for the three output parameters plotted against the true values. As in Figure 11, we have split the parameter space into hexagonal bins and used a logarithmic color scale to denote the number of galaxies in each bin. The purpose of this plot is to identify regions of parameter space where GaMPEN performs especially well or badly, so that, in the future, we can flag predictions in these regions as very secure or unreliable. Note that because we are performing the test here on simulated galaxies, we have access to the ground-truth values. However, in a scenario where GaMPEN is being used on real galaxies which have not been morphologically studied before, we will not have access to the ground-truth values, and any such cuts on the x-axis would need to be made based on the values predicted by GaMPEN. Thus, we created Figure 14, where we replaced the x-axis with the predicted values of the parameters instead of the true values.
Figure 13. Residuals of GaMPEN predicted parameter values plotted against the true values. The residual for each parameter is defined as the difference between the most probable predicted value and the true value, i.e., 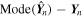 . The color of each hexagonal bin corresponds to the number of galaxies it contains, as shown by the color bar on the right. The black dotted line (y = 0) represents perfectly recovered parameters.
. The color of each hexagonal bin corresponds to the number of galaxies it contains, as shown by the color bar on the right. The black dotted line (y = 0) represents perfectly recovered parameters.
Download figure:
Standard image High-resolution image
Figure 14. Residuals of the output parameters plotted against the predicted values. This figure allows us to assign quality labels to GaMPEN predictions (e.g., flagging parameters that are unreliable) based on the output values. See Section 6.4 for details.
Download figure:
Standard image High-resolution imageIn both Figures 13 and 14, for most of the panels, the large majority of galaxies are clustered uniformly around the black dashed line, y = 0, which denotes the ideal case of perfectly recovered parameters.
There are a few other notable features in these two figures. In the top-left panel, the LB /LT residuals are highest near the limits of LB /LT . This is another manifestation of the edge effect mentioned earlier, wherein sometimes machine-learning algorithms perform poorly at the edges of the parameter space on which they were trained. To delve deeper, we looked at the LB /LT residuals separately for double and single-component galaxies, as shown in Figure 15. For single-component galaxies, the typical LB /LT residual (σ = 0.06) is roughly half as large as for double-component galaxies (σ = 0.11); among the latter, the residuals are especially high when LB /LT > 0.85 or LB /LT < 0.1. In other words, accurately determining LB /LT is challenging when both a bulge and a disk are present, and becomes even more difficult when one component strongly dominates the other. Larger residuals in the predictions near the limits of LB /LT leads to the features seen in the top-left panel of both figures.
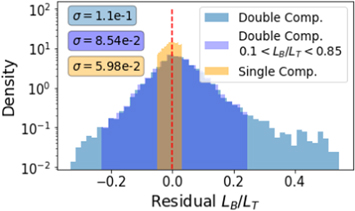
Figure 15. Histograms of LB /LT residuals shown separately for single-component galaxies, all double-component galaxies, and double-component galaxies with 0.1 < LB /LT < 0.85. The standard deviation (σ) for each distribution is also shown in the top left. The dashed vertical line represents x = 0, denoting cases with perfectly recovered LB /LT . The apparent hard cutoffs in the distributions of the single-component, and the restricted range double-component galaxies arise from the fact that the y-scale is logarithmic. We have verified that when plotted on a linear scale, the apparent hard cutoffs disappear.
Download figure:
Standard image High-resolution imageThis edge effect also results in the top and bottom streaks seen in the left panel of Figure 11. Given the logarithmic color bar used in this figure, note that most of the galaxies in the upper streak have true LB /LT > 0.75 and those in the bottom streak have true LB /LT < 0.25. For these cases, when one component completely dominates over the other component, precisely determining LB /LT is challenging. For some of the galaxies with 0.25 > true LB /LT > 0.75, GaMPEN assigns almost the entirety of the light to the dominant component, resulting in the streaks in the left panel. We use a parameter transformation to mitigate this edge effect, as described in Section 6.4.
In the top-middle panels of Figures 13 and 14, there is a slight broadening of the residuals at low values of the effective radius. This result also makes sense: smaller galaxies are challenging to analyze for any image processing algorithm. Somewhat surprising features appear in the panels showing residuals of effective radius (middle row, middle column) and flux (bottom row, right column). The Re
residuals increase in magnitude (with a bias toward negative values) toward increasing values of Re
, and the residual flux also grows rapidly with higher flux values. However, these increases are simply the result of the increasing numerical values of the parameters. To show this, Figure 16 plots the dimensionless fractional Re
and F residuals (note that LB
/LT
is inherently dimensionless), using their absolute values, such that the ideal scenario (i.e., zero residuals) is at the bottom of each panel instead of in the middle. In this presentation, both features noted above not only disappear but reverse. For small values of effective radius, Re
< 10, there is an increase in the magnitude of the residuals. Similarly, the right two panels show that the residuals of Re
and F are systematically higher for faint galaxies, F < 106 nJy.
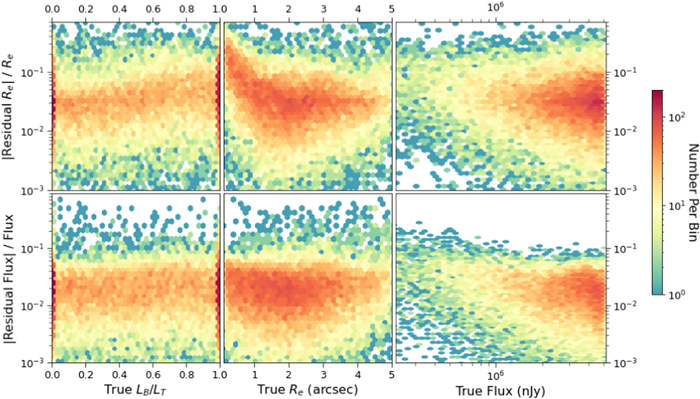
Figure 16. Fractional residuals for the effective radius and flux plotted against their corresponding true values. Note that since we are plotting the absolute values, the ideal situation of perfectly recovered parameters is at the bottom of each panel. The right two panels show that both the residuals increase for fainter galaxies, while the top-middle panel shows that the radius residuals increase for smaller galaxies.
Download figure:
Standard image High-resolution imageIn other words, GaMPEN systematically becomes less accurate at predicting the radii of galaxies when their sizes become comparable to the seeing of the HSC-Wide Survey (g-band median FWHM ∼085). Similarly, GaMPEN finds it more challenging to predict the sizes and fluxes of fainter galaxies, just as one would expect. With our previously published classification network, GaMorNet (Ghosh et al. 2020), we observed a similar reduction in prediction accuracy for smaller and fainter galaxies. Figures 13, 14, and 16 help quantify the errors in GaMPEN predictions in different regions of parameter space. These will be essential in order to interpret results appropriately when applying GaMPEN to real galaxies.
6.3. Inspecting the Predicted Uncertainties
The primary advantage of a Bayesian machine-learning framework like GaMPEN is its ability to predict the full posterior distributions of the output parameters instead of just point estimates. Thus, we would expect such a network to inherently produce wider distributions (i.e., larger uncertainties) in regions of the parameter space where residuals are higher. Here we delineate regions of the parameter space for which GaMPEN predicts broader distributions and we see that these generally coincide with those that have the largest residuals (Figures 13, 14, and 16).
Figure 17 shows the uncertainties for the three predicted parameters plotted against the true values of the different parameters. We define the uncertainty predicted for each parameter as the width of the 68.27% confidence interval (i.e., the parameter interval that contains 68.27% of the most probable values of the predicted distribution; see Figure 10). The lower two panels have been normalized, so that all three panels show dimensionless fractional uncertainties.
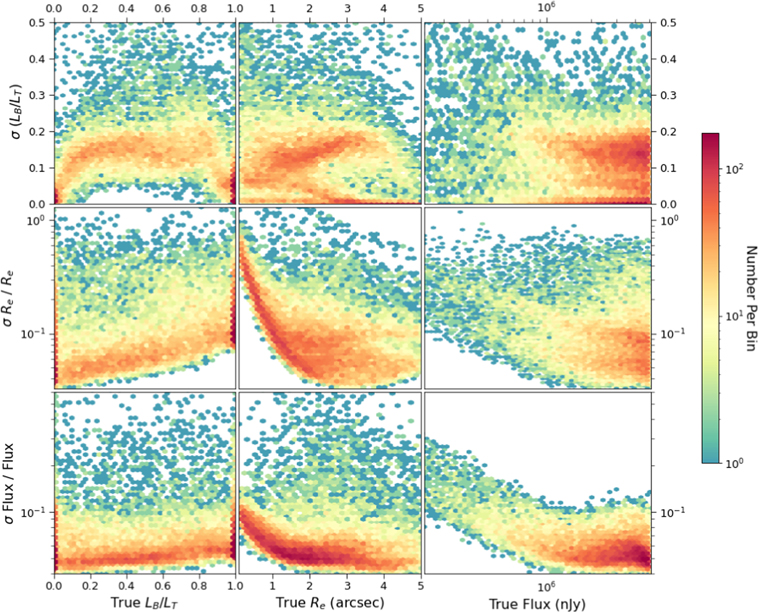
Figure 17. Uncertainties predicted by GaMPEN for each parameter plotted against the true values. The σ for each parameter is defined as the width of the 68.27% confidence interval. Note that we plot fractional uncertainties for radius and flux in order to make the y-axis dimensionless for all three rows.
Download figure:
Standard image High-resolution imageThe uncertainties in the predicted values of the radius increase sharply for galaxies with Re < 2″ and/or F < 106 nJy. Similarly, the uncertainties in flux increase for galaxies with Re < 1″ and/or F < 106 nJy. This aligns perfectly with what we expect: the sizes and fluxes of small galaxies and/or faint galaxies are not well constrained. Just as the residuals for GaMPEN predictions were larger for small and/or faint galaxies (Figures 13, 14, and 16), the uncertainties predicted by GaMPEN are also larger for these galaxies.
The top-left panel of Figure 17 shows that GaMPEN is reasonably certain of its predicted bulge-to-total-light ratio across the full range of values but appears slightly more certain when LB /LT ≤ 0.2 or LB /LT ≥ 0.8. It turns out that the smaller uncertainties at the limits correspond to the single-component galaxies, while for the double-component galaxies, the edge effect is less pronounced, in agreement with the residuals observed in Figure 15. Not surprisingly, the predicted uncertainty in Re decreases with decreasing values of LB /LT (i.e., galaxies with more dominant disks, which are on average larger than bulge-dominated galaxies in our simulation sample).
In Figure 18, we further assess the estimated uncertainties by investigating their relation to the measured residuals. Note that while the uncertainties represent the widths of the central 68.27% confidence intervals, the residuals are the difference between the modes of the predicted distributions and the true values. Thus, we do not expect the two values to be linearly correlated; rather, on average, GaMPEN should predict larger uncertainties for galaxies with larger residuals, as is seen in all three panels of the figure. According to a Spearman’s rank correlation test (see Dodge 2008, for more details), there is a positive correlation between the residuals and uncertainties for all three variables, and the null hypothesis of non-correlation can be rejected at extremely high significance (p < 10−200).
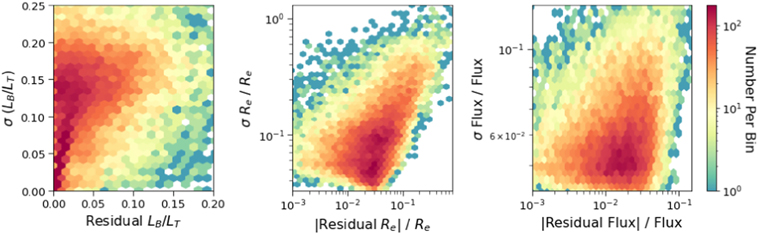
Figure 18. Uncertainties (widths of the 68.27% confidence intervals) predicted by GaMPEN for each parameter vs. the corresponding residuals (predicted mode minus true value). Fractional uncertainties and residuals are plotted for radius and flux in order to make all the quantities dimensionless. The trend in all three cases is that GaMPEN-estimated uncertainties increase for cases where its predictions are less accurate. The coverage probabilities reported on the test set (Table 2) confirm that the predicted uncertainties are well calibrated and correspond well to the quoted confidence intervals.
Download figure:
Standard image High-resolution imageThe results shown in this section outline the primary advantage of using a Bayesian framework like GaMPEN—even in situations where the network is not perfectly accurate, it is able to predict the right level of precision, allowing its predictions to be reliable and well calibrated.
6.4. Qualitative Transformation of GaMPEN Predictions
Given that we know GaMPEN residuals are higher for certain regions of the parameter space, we explore how using only qualitative labels in those regions (instead of quantitative predictions) affects the overall residual values. The labeling is informed by the results of Section 6.2 and the labels are assigned by us based on the parameter values predicted by GaMPEN. The labels are applied based on the predicted values of GaMPEN because we will not have access to true values of the parameters when applying GaMPEN to previously unanalyzed real galaxies. This is crucial given that when we apply GaMPEN to real data, techniques like this will provide us practical tools to deal with predictions in regions of the parameter space where we know GaMPEN to be less accurate.
For the bulge-to-total-light ratio, we retain GaMPEN’s numerical predictions for 0.1 < LB /LT < 0.85, but label the more extreme galaxies as highly bulge dominated (LB /LT ≥ 0.85) or highly disk dominated (LB /LT ≤ 0.1). The top-left panel of Figure 19 shows the two labeled regions (black-shaded grid), which is where the residuals are highest. The right panel of the top row shows the residual distributions including and excluding the extreme cases. As indicated by the standard deviation (top right corner), removing these extreme cases eliminates the largest errors in the predicted values of LB /LT . We also checked the accuracy of our assigned labels, and show the confusion matrix in Figure 20. From this, we calculate the net accuracy of our extreme LB /LT labels to be ⪆99%.
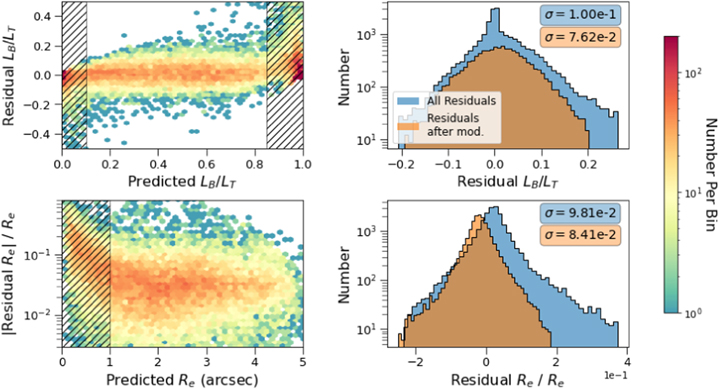
Figure 19. The left panels show the residuals for bulge-to-total-light ratio and radius plotted against their predicted values. The black dashed regions show the parameter space where we replace the quantitative predictions with qualitative flags. Each corresponding histogram on the right shows the distribution of residuals before and after the transformation of output values.
Download figure:
Standard image High-resolution image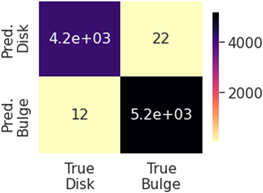
Figure 20. Confusion matrix between the labels we assign when GaMPEN predicts extreme bulge-to-total-light ratios, LB /LT < 0.1 or >0.85, and their true LB /LT values. The number in each block shows how many galaxies correspond to that panel, resulting in an overall accuracy >99%.
Download figure:
Standard image High-resolution imageWe apply similar labels to small predicted values of the effective radius. As shown in the bottom row of Figure 19, we flag galaxies with Re
< 10 with the label “galaxy with Re
< 1″” in place of the exact numerical value. This reduces the typical error for Re
, as shown in the histogram on the right. We calculate the accuracy of this label to be ∼97%.
Thus, replacing GaMPEN’s quantitative predictions in certain small regions of the parameter space with qualitative flags results in a reduction of the typical residuals as well as highly accurate qualitative predictions.
7. Discussion and Conclusions
In this work, we introduced GaMPEN, a machine-learning framework that can estimate posterior distributions for a galaxy’s bulge-to-total-light ratio, effective radius, and flux. Although GaMPEN was trained to estimate these specific parameters, it can be adapted by users easily to predict other/additional morphological parameters (e.g., axis ratio, position angle, etc.). One important consideration while choosing how many parameters to predict using a single GaMPEN framework is that the number of terms in the covariance matrix will increase as  , where n is the number of output variables. Although the computation time will increase at a much less steep rate, the exact nature of the increase will depend on the specifics of the hardware being used.
, where n is the number of output variables. Although the computation time will increase at a much less steep rate, the exact nature of the increase will depend on the specifics of the hardware being used.
We trained GaMPEN on two NVIDIA Tesla P100/V100 GPUs with each training run taking about ∼12–16 hr. GaMPEN is designed to use multiple GPUs during training and using more GPUs can reduce this training time even further. Our hyperparameter search required ∼30 runs. Given that we expect ∼100,000 images to always be enough to train GaMPEN, our framework can easily be trained on other data sets within a similar reasonable timescale. Once trained, it takes GaMPEN less than a millisecond to process each input galaxy image. Thus, to predict distributions (∼1000 inference runs for each image) for a million galaxies on two GPUs, GaMPEN needs ∼5 days of runtime. Therefore, GaMPEN can be used to process data from future large surveys like LSST, NGRST, and Euclid within a reasonable timescale.
Training and testing GaMPEN on galaxies simulated to match Hyper Suprime-Cam Wide g-band z < 0.25 data, we found excellent agreement between the coverage probabilities and the corresponding confidence thresholds (Table 2). This demonstrates that GaMPEN predicted posterior distributions are calibrated and accurate.
To account for both aleatoric and epistemic uncertainties in GaMPEN predictions, we incorporated the full covariance matrix in our loss function and used the Monte Carlo dropout technique. Using the covariance matrix also allowed us to incorporate the structured relationships among the output parameters into GaMPEN predictions. This made it possible to achieve the simultaneous calibration of the posteriors of all three output variables (Figure 8). In order to incorporate the covariance matrix in the loss function, we used the Cholesky decomposition and a set of linear algebraic tricks (Section 4.3).
The typical values of errors in GaMPEN predictions are 0.10, 017 (∼7%), and 6.3 × 104 nJy (∼1%), for LB
/LT
, Re
, and F, respectively. The error in GaMPEN predictions of Re
increases when Re
< 1″ (i.e., when Re
becomes comparable to the seeing of the HSC-Wide survey) and/or F < 106 nJy. Galaxies fainter than 106 nJy also result in higher flux residuals. These trends result from the inherent challenge in analyzing small and faint galaxies. GaMPEN accounts for these high residuals by correctly predicting higher uncertainties in Re
and F for smaller and fainter galaxies. In other words, GaMPEN predicts broader distributions in regions where it is less precise.
The residuals in GaMPEN predictions of LB /LT are high for LB /LT ∼ 0 and ∼1. We demonstrate that by applying qualitative labels for 0.1 ≥ LB /LT ≥ 0.85 instead of quantitative values, we can reduce the typical error in LB /LT to 0.076. The produced qualitative labels (in the regions with high residuals) have extremely high accuracies of ⪆99%. Similarly, by labeling predictions for Re < 1″, we achieve a similar reduction in the typical Re residual, and the produced labels are highly accurate. Thus, the qualitative transformation of the output values gives us tools to deal with regions of the parameter space where residuals in GaMPEN predictions are high.
It is difficult to accurately compare GaMPEN's performance to existing morphology parameter estimation pipelines (such as GALFIT (Peng et al. 2002), GIM2D (Simard et al. 2002), or Tuccillo et al. (2018)'s neural network) primarily due to the fact that none of them estimate Bayesian posteriors for the predicted parameters. GALFIT and GIM2D do include analytical estimates of errors, but Haussler et al. (2007) found that both these algorithms severely underestimate the true uncertainties by an extremely large factor (≥70% for most galaxies). In contrast, GaMPEN's predicted uncertainties are well calibrated and accurate (<5% deviation). Although GaMPEN's predictions are best used and interpreted in a probabilistic context, we compare below GaMPEN's residuals (assuming the most probable value to be the predicted value) to the residuals achieved by other frameworks.
Meert et al. (2013) used GALFIT to fit two-component light profiles to simulated SDSS (York et al. 2000) galaxies and found the typical Re error to be 10% and the typical magnitude error to be 0.075 mag. GaMPEN achieves a typical Re error of ∼7% and a typical magnitude error of 0.051 mag. Haussler et al. (2007) used single-component fits to analyze simulated galaxies in the Hubble Space Telescope (HST) Galaxy Evolution from Morphology and SEDs (GEMS; Rix et al. 2004) survey using GALFIT and GIM2D. They found the typical error in magnitude to be 0.05 mag using GALFIT and 0.10 mag using GIM2D. They found the typical ratio between the predicted and true Re to be 0.98 ± 0.06 using GALFIT and 1.01 ± 0.11 using GIM2D. The same value for GaMPEN is 0.98 ± 0.08. Tuccillo et al. (2018) used a CNN to obtain predictions for the parameters of a single-component Sérsic fit using simulations of HST Cosmic Assembly Near-Infrared Deep Extragalactic Legacy Survey (CANDELS; Grogin et al. 2011) galaxies and reported the degree of regression accuracy defined as
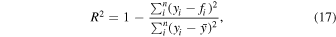
where fi
is the predicted value of the true variable yi
and 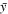 is the mean over all n samples. The R2 for magnitude and Re
were reported to be 0.997 and 0.972, respectively. The authors also analyzed the same galaxies using GALFIT and found the corresponding R2 to be 0.983 and 0.877. The R2 achieved by GaMPEN for magnitude and Re
are 0.998 and 0.980, respectively. While Haussler et al. (2007) and Tuccillo et al. (2018) did not have estimates of LB
/LT
(as they used single-component fits), Meert et al. (2013) did not report their residuals for LB
/LT
. Thus, it was not possible to compare GaMPEN's LB
/LT
residuals with these previous works. Although none of the above represent absolutely equivalent comparisons, they indicate that GaMPEN's prediction accuracy is comparable to the most popular state-of-the-art morphology prediction tools.
is the mean over all n samples. The R2 for magnitude and Re
were reported to be 0.997 and 0.972, respectively. The authors also analyzed the same galaxies using GALFIT and found the corresponding R2 to be 0.983 and 0.877. The R2 achieved by GaMPEN for magnitude and Re
are 0.998 and 0.980, respectively. While Haussler et al. (2007) and Tuccillo et al. (2018) did not have estimates of LB
/LT
(as they used single-component fits), Meert et al. (2013) did not report their residuals for LB
/LT
. Thus, it was not possible to compare GaMPEN's LB
/LT
residuals with these previous works. Although none of the above represent absolutely equivalent comparisons, they indicate that GaMPEN's prediction accuracy is comparable to the most popular state-of-the-art morphology prediction tools.
GaMPEN contains an STN that enables it to crop the input image automatically. We demonstrated that GaMPEN does this based on galaxy size, without any need for specific instruction. Because the transformation is differentiable, loss gradients can be backpropagated, and thus the STN can be trained along with the rest of the framework without any additional supervision. The STN in GaMPEN will empower us to apply it to future large data sets over a broad range of redshifts without having to worry about optimal cutout sizes.
Although in recent years there has been a significant increase in the use of CNNs for morphological determination, GaMPEN is the first machine-learning framework that can robustly estimate posterior distributions of multiple morphological parameters. GaMPEN is also the first application of an STN to optical imaging in astronomy.
By testing GaMPEN on simulated HSC g-band galaxies, where we have access to robust ground-truth values, we demonstrated its effectiveness in recovering morphological parameters and we quantified errors/uncertainties in GaMPEN predictions across different regions of the parameter space.
Note that, for this work, we trained and tested GaMPEN on single-band images. However, we have tested and verified that both the CNN and STN in GaMPEN can be easily adapted to intake an arbitrary number of channels, with each channel being a different band. To obtain separate morphological parameters for each band, the number of output parameters would need to be increased appropriately. We will perform a detailed evaluation of GaMPEN's performance on multiband images in future work.
In this work, we performed a thorough analysis of GaMPEN's performance using HSC z < 0.25 simulations. However, GaMPEN can be applied to a wide variety of other data sets—including real HSC images, imaging from other ground and space-based observatories as well as higher redshift data. However, in order to apply GaMPEN to real data, one would need to perform appropriate transfer learning (i.e., fine-tuning the simulation trained GaMPEN models using a small amount of data from the application data set). We refer an interested reader to Ghosh et al. (2020), where we performed transfer learning and demonstrated the application of our classification framework, GaMorNet, to SDSS z ∼ 0 and CANDELS z ∼ 1 data.
Just like other image analysis methods, we expect GaMPEN's performance to change based on the quality of the images being used (e.g., the pixel scale of the survey, the noise, the redshift of the object). We will explore how GaMPEN performs in each of these above situations in future work.
The authors would like to thank the anonymous referee for their insightful, encouraging, and extremely thorough comments about our manuscript. Their constructive criticism greatly assisted us in improving the manuscript, extending the discussion section, and making it more accessible to readers.
This material is based upon work supported by the National Science Foundation under grant No. 1715512.
C.M.U. and A.G. would like to acknowledge support from the National Aeronautics and Space Administration via ADAP grant 80NSSC18K0418.
A.G. would like to acknowledge support received from the Yale Graduate School of Arts & Sciences through the Dean’s Emerging Scholars Research Award.
A.G. would like to acknowledge computing grants received through the Amazon Cloud Credits for Research Program and the Yale Center for Research Computing (YCRC) Research Credits Program. A.G. would also like to acknowledge computing support from YCRC and Yale Information Technology Services staff members and scientists.
E.T. acknowledges support from FONDECYT Regular 1190818 and 1200495, ANID grants CATA-Basal AFB-170002, ACE210002, and FB210003, and Millennium Nucleus NCN19_058.
The Hyper Suprime-Cam (HSC) Collaboration includes the astronomical communities of Japan and Taiwan, and Princeton University. The HSC instrumentation and software were developed by the National Astronomical Observatory of Japan (NAOJ), the Kavli Institute for the Physics and Mathematics of the Universe (Kavli IPMU), the University of Tokyo, the High Energy Accelerator Research Organization (KEK), the Academia Sinica Institute for Astronomy and Astrophysics in Taiwan (ASIAA), and Princeton University. Funding was contributed by the FIRST program from Japanese Cabinet Office, the Ministry of Education, Culture, Sports, Science and Technology (MEXT), the Japan Society for the Promotion of Science (JSPS), Japan Science and Technology Agency (JST), the Toray Science Foundation, NAOJ, Kavli IPMU, KEK, ASIAA, and Princeton University.
This paper makes use of software developed for the Large Synoptic Survey Telescope. We thank the LSST Project for making their code available as free software at http://dm.lsst.org.
The Pan-STARRS1 Surveys (PS1) have been made possible through contributions of the Institute for Astronomy, the University of Hawaii, the Pan-STARRS Project Office, the Max-Planck Society and its participating institutes, the Max Planck Institute for Astronomy, Heidelberg and the Max Planck Institute for Extraterrestrial Physics, Garching, The Johns Hopkins University, Durham University, the University of Edinburgh, Queens University Belfast, the Harvard-Smithsonian Center for Astrophysics, the Las Cumbres Observatory Global Telescope Network Incorporated, the National Central University of Taiwan, the Space Telescope Science Institute, the National Aeronautics and Space Administration under Grant No. NNX08AR22G issued through the Planetary Science Division of the NASA Science Mission Directorate, the National Science Foundation under Grant No. AST-1238877, the University of Maryland, and Eotvos Lorand University (ELTE) and the Los Alamos National Laboratory.
Based, in part, on data collected at the Subaru Telescope and retrieved from the HSC data archive system, which is operated by Subaru Telescope and Astronomy Data Center at National Astronomical Observatory of Japan.
Software: PyTorch (Paszke et al. 2019), Ignite (Fomin et al. 2020), MLFlow (Chen et al. 2020), NumPy (Harris et al. 2020), Astropy (Robitaille et al. 2013; Price-Whelan et al. 2018), Pandas (McKinney 2010), Scikit-learn (Pedregosa et al. 2011), Matplotlib (Hunter 2007), Corner (Foreman-Mackey 2016).
Appendix A: Early Data Access
Currently, we are applying GaMPEN to real data, and will make the source code public in the Fall of 2022, along with documentation, tutorials, and trained models. Readers interested in using GaMPEN before the full public release can access the source code and trained models of GaMPEN by emailing the corresponding author of this paper.
The public data release for GaMPEN will be hosted at the following two locations:
- 1.
- 2.
Appendix B: Extended Derivation for Bayesian Implementation of GaMPEN
In variational inference, the posterior, 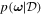 in Equation (6), is replaced by an approximate variational distribution with an analytic form q(
ω
). Now, Equation (6) can be written as
in Equation (6), is replaced by an approximate variational distribution with an analytic form q(
ω
). Now, Equation (6) can be written as
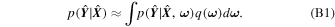
The choice of the variational distribution is arbitrary. One such choice, introduced by Gal & Ghahramani (2016), involves dropping different neurons from some layers in order to assess the impact on the model. The dropout technique was introduced by Srivastava et al. (2014) in order to prevent neural networks from overfitting; they temporarily removed random neurons from the network according to a Bernoulli distribution, i.e., individual nodes were set to zero with a probability, p, known as the dropout rate.
In the variational application, we use dropouts to interrogate the model. Specifically, if pi is the probability of a neuron being turned off, and ![${\left[{z}_{i,j}\right]}_{j=1}^{{J}_{i-1}}$](https://content.cld.iop.org/journals/0004-637X/935/2/138/revision6/apjac7f9eieqn60.gif) is a vector of length Ji−1 containing the Bernoulli-distributed random variables for unit j = 1,…,Ji−1 in the
is a vector of length Ji−1 containing the Bernoulli-distributed random variables for unit j = 1,…,Ji−1 in the  layer with probabilities pi, then
layer with probabilities pi, then
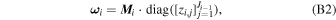
where M i is the Ji × Ji−1 matrix of variational parameters to be optimized.
Thus, sampling from q( ω ) is now equivalent to using dropouts on a set of layers, with weights M (i.e., M i for the ith layer). We perform inference on the trained network by approximating Equation (B1) with a Monte Carlo integration:
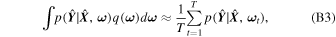
wherein we perform T forward passes with dropout enabled and ω t is the set of weights during the tth forward pass.
Appendix C: Extended Derivation of the Loss Function
As outlined in Equation (6), we seek the most likely set of model parameters given our training data, i.e., we maximize
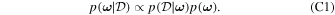
In Equation (C1), p( ω ) is the prior on the neural networks weights. The weight prior here is unimportant and what matters is the prior induced on the output parameters of GaMPEN. And as outlined above, we use an uninformative multivariate Gaussian prior to induce an uninformative prior on the output. Please refer to Wilson (2020) for a detained discussion on priors in Bayesian deep learning.
For a regression task using a standard CNN, wherein the network outputs predictions 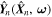 for true values
Y
n
, one popular choice is to minimize the squared-error loss function
for true values
Y
n
, one popular choice is to minimize the squared-error loss function 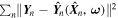 , where the sum over n denotes a sum over the training set. However, in contrast to the traditional approach, for each new test image
, where the sum over n denotes a sum over the training set. However, in contrast to the traditional approach, for each new test image 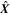 , GaMPEN needs to predict the parameters of a multivariate Gaussian distribution,
, GaMPEN needs to predict the parameters of a multivariate Gaussian distribution, 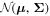 .
.
Now, as discussed in Section 4.1, we replace  in Equation (6) with an approximating variational distribution q(
ω
). This is performed by minimizing their Kullback–Leibler (KL) divergence, a measure of the similarity between two distributions. Since minimizing the KL divergence is equivalent to maximizing the log-evidence lower bound,
in Equation (6) with an approximating variational distribution q(
ω
). This is performed by minimizing their Kullback–Leibler (KL) divergence, a measure of the similarity between two distributions. Since minimizing the KL divergence is equivalent to maximizing the log-evidence lower bound,
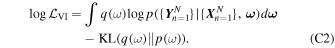
The first term in Equation (C2) is the log-likelihood for the output parameters for the training set, and as shown in Gal & Ghahramani (2016), the KL term can be approximated as an L2 regularization. Therefore, Equation (C2) can be written as
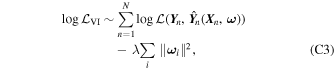
where  is the log-likelihood of the network predictions
is the log-likelihood of the network predictions  for training input
X
n
with true values
Y
n
, λ is the strength of the regularization term, and
ω
i
are sampled from q(
ω
).
for training input
X
n
with true values
Y
n
, λ is the strength of the regularization term, and
ω
i
are sampled from q(
ω
).
For the multivariate Gaussian distribution predicted by GaMPEN,  , we can write the log-likelihood of the network predictions (first term on the right side in Equation (C3)) as
, we can write the log-likelihood of the network predictions (first term on the right side in Equation (C3)) as
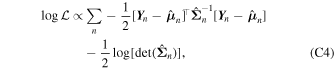
where  and
and  are the mean and covariance matrix of the multivariate Gaussian distribution predicted by GaMPEN for an image,
X
n
.
are the mean and covariance matrix of the multivariate Gaussian distribution predicted by GaMPEN for an image,
X
n
.
We train GaMPEN by minimizing the negative log-likelihood of the output parameters for the training set, which by combining Equations (C3) and (C4), can be written as
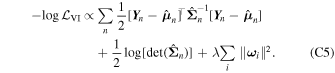
Appendix D: Additional Technical Details on GaMPEN
In Table 3, we have outlined the various layers of the GaMPEN framework along with the important parameters of each layer and the corresponding activation functions.
Table 3. Structure of GaMPEN
| Order | Type of Layer | Layer Description | Activation Function |
|---|---|---|---|
| Upstream Spatial Transformer Network | |||
| 1 | Input | Size: 239 × 239 | ⋯ |
| 2 | Convolutional | No. of filters: 64 ∣filter size: 11 | ReLU a |
| 3 | Max pooling | Kernel size: 3 ∣strides: 2 | ⋯ |
| 4 | Convolutional | No. of filters: 96 ∣filter size: 9 | ReLU |
| 5 | Max pooling | Kernel size: 3 ∣strides: 2 | ⋯ |
| 6 | Fully connected | No. of neurons: 32 | ReLU |
| 7 | Fully connected | No. of neurons: 1 | Linear |
| Downstream Morphological Estimation Network | |||
| 1 | Input | Size: 239 × 239 | ⋯ |
| 2 | Convolutional | No. of filters: 64 ∣filter size: 3 ∣strides: 1 | ReLU |
| 3 | Dropout | ⋯ | ⋯ |
| 4 | Convolutional | No. of filters: 64 ∣filter size: 3 ∣strides: 1 | ReLU |
| 5 | Max pooling | Kernel size: 2 ∣strides: 2 | ⋯ |
| 6 | Dropout | ⋯ | ⋯ |
| 7 | Convolutional | No. of filters: 128 ∣filter size: 3 ∣strides: 1 | ReLU |
| 8 | Dropout | ⋯ | ⋯ |
| 9 | Convolutional | No. of filters: 128 ∣filter size: 3 ∣strides: 1 | ReLU |
| 10 | Max pooling | Kernel size: 2 ∣strides: 2 | ⋯ |
| 11 | Dropout | ⋯ | ⋯ |
| 12 | Convolutional | No. of filters: 256 ∣filter size: 3 ∣strides: 1 | ReLU |
| 13 | Dropout | ⋯ | ⋯ |
| 14 | Convolutional | No. of filters: 256 ∣filter size: 3 ∣strides: 1 | ReLU |
| 15 | Dropout | ⋯ | ⋯ |
| 16 | Convolutional | No. of filters: 256 ∣filter size: 3 ∣strides: 1 | ReLU |
| 17 | Max pooling | Kernel size: 2 ∣strides: 2 | ⋯ |
| 18 | Dropout | ⋯ | ⋯ |
| 19 | Convolutional | No. of filters: 512 ∣filter size: 3 ∣strides: 1 | ReLU |
| 20 | Dropout | ⋯ | ⋯ |
| 21 | Convolutional | No. of filters: 512 ∣filter size: 3 ∣strides: 1 | ReLU |
| 22 | Dropout | ⋯ | ⋯ |
| 23 | Convolutional | No. of filters: 512 ∣filter size: 3 ∣strides: 1 | ReLU |
| 24 | Max pooling | Kernel size: 2 ∣strides: 2 | ⋯ |
| 25 | Dropout | ⋯ | ⋯ |
| 26 | Convolutional | No. of filters: 512 ∣filter size: 3 ∣strides: 1 | ReLU |
| 27 | Dropout | ⋯ | ⋯ |
| 28 | Convolutional | No. of filters: 512 ∣filter size: 3 ∣strides: 1 | ReLU |
| 29 | Dropout | ⋯ | ⋯ |
| 30 | Convolutional | No. of filters: 512 ∣filter size: 3 ∣strides: 1 | ReLU |
| 31 | Max pooling | Kernel size: 2 ∣strides: 2 | ⋯ |
| 32 | Fully connected | No. of neurons: 4096 | ReLU |
| 33 | Dropout | ⋯ | ⋯ |
| 34 | Fully connected | No. of neurons: 4096 | ReLU |
| 35 | Dropout | ⋯ | ⋯ |
| 36 | Fully connected | No. of neurons: 9 | Linear |
Note.
a Rectified Linear Unit.The dropout rate of the various layers are set according to the calibration step described in Section 5.
Download table as: ASCIITypeset image
Footnotes
- 15
CNNs are a specific form of machine-learning algorithm that specializes in processing data with a grid-like topology, such as an image. See Section 3 for more details.
- 16
- 17