Abstract
X-ray binaries (XRBs) consist of a compact object that accretes material from an orbiting secondary star. The most secure method we have for determining if the compact object is a black hole is to determine its mass: This is limited to bright objects and requires substantial time-intensive spectroscopic monitoring. With new X-ray sources being discovered with different X-ray observatories, developing efficient, robust means to classify compact objects becomes increasingly important. We compare three machine-learning classification methods (Bayesian Gaussian Processes (BGPs), K-Nearest Neighbors (KNN), Support Vector Machines) for determining whether the compact objects are neutron stars or black holes (BHs) in XRB systems. Each machine-learning method uses spatial patterns that exist between systems of the same type in 3D color–color–intensity diagrams. We used lightcurves extracted using 6 yr of data with MAXI/GSC for 44 representative sources. We find that all three methods are highly accurate in distinguishing pulsing from nonpulsing neutron stars (NPNS) with 95% of NPNS and 100% of pulsars accurately predicted. All three methods have high accuracy in distinguishing BHs from pulsars (92%) but continue to confuse BHs with a subclass of NPNS, called bursters, with KNN doing the best at only 50% accuracy for predicting BHs. The precision of all three methods is high, providing equivalent results over 5–10 independent runs. In future work, we will suggest a fourth dimension be incorporated to mitigate the confusion of BHs with bursters. This work paves the way toward more robust methods to efficiently distinguish BHs, NPNS, and pulsars.
Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
X-ray binaries (XRBs) consist of a compact object accreting matter from a main-sequence or supergiant companion star, orbiting the common center of mass. They are often identified as low-mass X-ray binaries (LMXBs, companion-star mass ≤1 M⊙) and high-mass X-ray binaries (HMXBs, companion-star mass ≥10 M⊙). In general, the compact object accretes matter through stellar wind capture in HMXBs and through Roche-lobe overflow in LMXBs. Both HMXBs and LMXBs can contain a black hole (BH), a nonpulsing neutron star (NPNS), or a pulsar as the compact object. They are further distinguished by the presence or absence of pulsations, jets, bursts, spectral characteristics that vary over time, and variations in luminosity (van Paradijs 1998).
The most reliable means of determining the nature of the compact object is by searching for the presence of a surface (pulsations, cyclotron resonance scattering features, thermonuclear bursts, etc.) or by determining the mass of the compact object using radial velocity measurements. Overall, very few reliable methods exist to determine the nature of the compact object in an XRB. In addition, these methods are limited to bright objects, requiring extensive monitoring by various ground-based and space-based telescopes. Although hundreds of XRB candidates have been identified in our galaxy (Liu et al. 2006, 2007) since their first discovery over 60 yr ago, we still lack a straightforward method for determining the nature of the compact objects.
An important means of studying their spectral characteristics is through the use of color–color (CC) and color–intensity (CI) diagrams. X-ray colors are defined as the ratio of photon counts in two X-ray energy bands. The information in CC diagrams captures the spectral states of XRBs while CI diagrams depict the variations in intensity over time. For example, NPNS systems are classified as Z or Atoll sources based on the shape they trace out in CC plots (Hasinger & van der Klis 1989). Z sources trace out a Z shape in X-ray CC diagrams while Atoll sources trace out banana-shaped or circular structures. However, it has been shown that the same source can exhibit both geometric patterns, depending on the mass accretion rate (Homan et al. 2010; Fridriksson et al. 2015). Often, different classes of XRBs also occupy overlapping regions in these two-dimensional representations (CC, CI).
In 2013, Vrtilek & Boroson (2013; hereafter VB13) proposed a three-dimensional representation (color–color–intensity, hereafter CCI) of XRBs that placed different classes into geometrically different regions, providing a model-independent means of separating the types. As a step toward understanding the physical mechanisms behind the separation seen by VB13, Gopalan et al. (2015, hereafter GP15) developed a probabilistic (Bayesian) model that uses a supervised-learning approach (unknown classifications are predicted using known classifications) to quantify the accuracy of predicting the type of an unknown XRB using the VB13 representation.
Pattnaik et al. (2021) tested the ability of six machine-learning (ML) methods to accurately classify the compact objects in LMXBs, with CC and CI diagrams using data from the Proportional Counter Array (PCA) on RXTE (Glasser et al. 1994). They found that the Random Forest (RF) and K-nearest Neighbors (KNN) methods gave the highest accuracies and specifically evaluated the performance of the RF. They found 87% accuracy of predictions for observations with a signal-to-noise ratio (S/N) between 100 and 1000; for lower-S/N data, they achieved 58% accuracy.
In this paper, we compare three ML techniques to determine which provides the most efficient and accurate means of identifying the nature of the compact object in both LMXBs and HMXBs. We used the 3D representation of data introduced by VB13. As demonstrated by Islam et al. (2021), CCI has the advantage over CC and CI individually, in that the geometric patterns it produces translate consistently to data from different instruments. The ML techniques we use—BGP, similar to GP15; KNN as used by Pattnaik et al. (2021); and Support Vector Machines (SVM)—are widely used and particularly suitable for capturing spatial patterns in three-dimensional data. We use data from the Monitor of All Sky X-ray Image (MAXI; Matsuoka et al. 2009) in the energy bands that Islam et al. (2021) demonstrated most clearly show the separation of systems containing different types of compact objects. The advantage of all-sky monitors such as RXTE/ASM or MAXI is that while RXTE/PCA had only pointed observations in time-limited windows for specific behaviors of the system, all-sky monitors have long-term monitoring that covers all stages of outbursts, states, and transitions.
This paper is organized as follows. In Section 2, we describe the observations from MAXI. In Section 3, we describe the mathematical foundations of the ML algorithms implemented. In Section 4, we describe how these ML methods were applied to our observations. In Section 5, we present our results. In Section 6, we compare the computational efficiency of the different methods. In Section 7, we provide a summary and conclusions.
2. Description of the Data
2.1. Observations
All the data used in this paper were obtained with the Gas Slit Camera (GSC; Mihara et al. 2002; Tomida et al. 2011) on board MAXI (Matsuoka et al. 2009). In operation since 2009, MAXI is the first astronomical mission to be operated on the International Space Station (ISS; Matsuoka et al. 2009; Sugizaki et al. 2011). MAXI has higher sensitivity and higher energy resolution than any other all-sky X-ray-monitors flown to date (Mihara et al. 2002; Tomida et al. 2011). GSC has a 1 day sensitivity of 9 mCrab (3σ) compared to 15 mCrab with RXTE/ASM (Levine et al. 1996) and 16 mCrab with Swift/BAT (Krimm et al. 2013). The GSC on MAXI covers the energy band from 2 to 30 keV and contains six units of Xe-gas proportional counters, which are assembled to cover wide fields of view of 15 × 160° (Sugizaki et al. 2011). In addition, MAXI provides on-demand processing to extract lightcurves in user-specified energy bands.
8
We specify the energy bands 2–3 (Low), 3–5 (Medium), and 5–12 keV (High), which are close to those used by VB13 and GP15 and demonstrated by Islam et al. (2021) to be effective in separating classes of XRBs.
In this paper, the soft colors (SC) are defined as
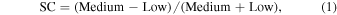
where Low and Medium refer to the counts in the 2–3 keV and 3–5 keV energy bands, respectively. The hard colors (HC) are defined as
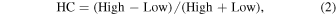
where High refers to the counts in the 5–12 keV energy band. Park et al. (2006) found that using this fractional difference ratio works well both in high-count and low-count regimes, whereas simple ratios or logarithms of ratios tend to fail in low-count regimes. After we compute SC and HC, we rescale them to match the scale of the relative intensity, which ranges from 0 to 1.
The relative intensity is computed by summing the counts in each of the energy bands (2–3 keV, 3–5 keV, and 5–12 keV) and then normalizing each source by the average of the top 0.01% of the counts to ensure the relative intensity is scaled from 0 to 1. The relative intensity (RelInt) can thus be written as

We only used detections with at least 3σ significance for each XRB observed by MAXI. For a data point to be statistically valid, we require that it has at least 3σ significance in the sum of the counts in the three energy bands. We achieve this by requiring that the counts in the individual energy bands be detected at the accuracy of 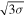 such that the total is summed in quadrature:
such that the total is summed in quadrature:
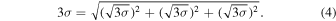
From each source, we also remove data points that deviate 10σ or greater from the mean as these outliers may be unphysical in origin (e.g., these outliers can appear when the reflection from solar panels comes into view). We demonstrate the effect of this 10σ cutoff in Figure 1. For some sources in the MAXI data set, we found that very few to no data points remain once checked for 3σ significance. This can happen because a source may vary in brightness and become fainter over time. For proper statistics, we considered only sources with at least 100 data points with 3σ significance (Figure 2).
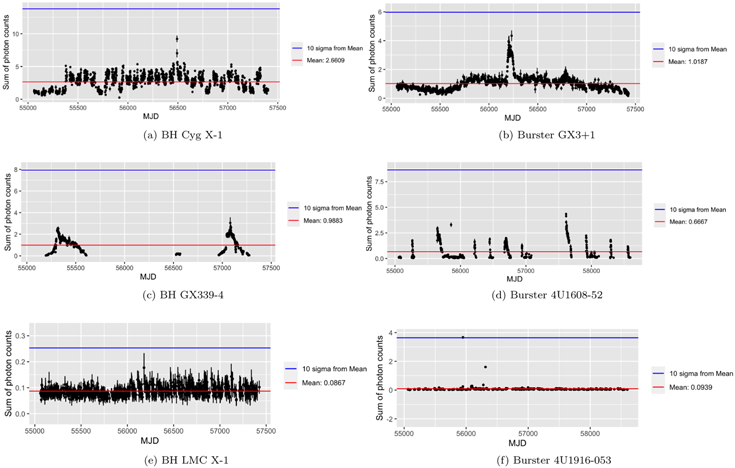
Figure 1. Example lightcurves of BHs (a), (c), (e) and bursters (b), (d), (f) showing the effect of the 10σ cutoff. The lightcurves are binned by 1 day.
Download figure:
Standard image High-resolution image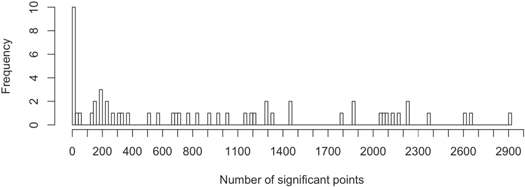
Figure 2. Histogram of the number of significant points for all sources. The frequency is the number of sources with this number of significant points. There is a clear cut around 100 points: 10 sources have 0 cts, and 2 are below 50 cts, whereas all the others have 120 cts or more.
Download figure:
Standard image High-resolution imageOf the 58 sources from MAXI that we checked, only 12 BHs, 20 NPNSs, and 12 pulsars matched our criteria for statistical significance. These 44 sources are listed in Table 1. The CCI diagram of all 44 sources is plotted in Figure 3, and their corresponding 2D projections are plotted in Figure 4. Because most of the BHs and some NPNS are transients, the sources that went into outburst during 16 yr of RXTE/ASM may or may not go into outburst during the 10 yr of MAXI operation. However, we have used new transients (which had not been active during the 16 yr of RXTE/ASM) that have been discovered by MAXI.
Figure 3. Color–color–intensity (CCI) diagrams of 12 BH (purple), 20 NPNS (orange), and 12 pulsar sources (green) from two different angles (35°, 145°). Each point represents two X-ray colors and the corresponding intensity over one day for a given XRB. An animation of this figure is available. In the animation, the figure rotates from 0° to 360° to illustrate the spatial patterns in the data. The real-time duration of the animation is 36 s. In the animation, we can see that pulsars occupy some of the same regions in the center as BHs and NPNSs, but they are generally more spatially separated from these other classes. BHs and NPNSs are spatially separated at lower values of HCs but overlap significantly at lower values of the relative intensities. The data behind this figure are also available.
(The data used to create this figure are available.)(An animation of this figure is available.)
Download figure:
Video Standard image High-resolution image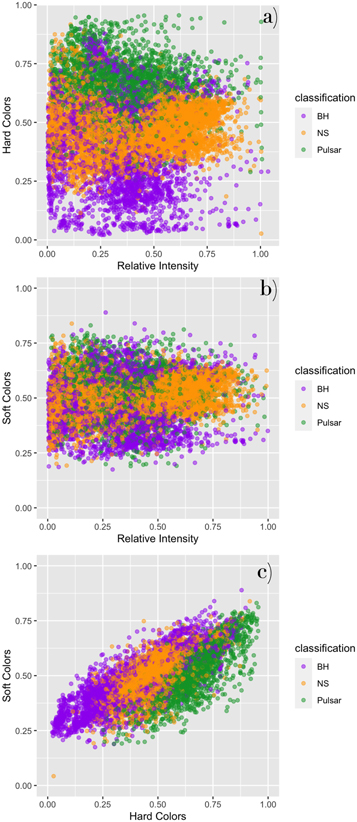
Figure 4. Two-dimensional projections of the color–color–intensity diagrams of all 44 XRB sources. (a) Relative intensity vs. HC for BHs (purple), NPNSs (orange), and pulsars (green). (b) Relative intensity vs. SC for BHs, NPNSs, and pulsars. (c) HCs vs. SCs for BHs, NPNSs, and pulsars.
Download figure:
Standard image High-resolution imageTable 1. X-Ray Binary Sources from MAXI Data
| Source | Compact | Source | Number of |
|---|---|---|---|
| Name | Object Type | Class | Significant Points |
| LMC X-3 | BH | HMBH, persistent | 765 |
| LMC X-1 | BH | HMBH, persistent | 821 |
| MAXI J1535–571 | BH Candidate | LMXB, transient | 306 |
| 4U1630–47 | BH Candidate | LMXB, transient | 679 |
| GX 339–4 | BH | LMBH, transient | 502 |
| GRS 1739–278 | BH Candidate | LMXB, transient | 1327 |
| H1743–322 | BH Candidate | LMXB, transient | 224 |
| MAXI J1820+070 | BH Candidate | LMXB, transient | 158 |
| GRS 1915+105 | BH | LMBH, transient | 1782 |
| Cyg X-1 | BH | HMBH, persistent | 1456 |
| 4U1957+115 | BH Candidate | LMXB, transient | 1298 |
| Cyg X-3 | BH Candidate | HMXB, persistent | 1284 |
| H0614+091 | Nonpulsing Neutron Star | LMNS, Burster | 2176 |
| 4U1254–690 | Nonpulsing Neutron Star | LMNS, Burster | 2915 |
| Cir X-1 | Nonpulsing Neutron Star | LMNS, Burster | 326 |
| 4U1608–52 | Nonpulsing Neutron Star | LMNS, Burster | 709 |
| Sco X-1 | Nonpulsing Neutron Star | LMNS | 2059 |
| H1636–536 | Nonpulsing Neutron Star | LMNS, Burster | 2228 |
| 4U1700–37 | Nonpulsing Neutron Star | HMNS | 1152 |
| GX 349+2 | Nonpulsing Neutron Star | LMNS | 2375 |
| 4U1705–44 | Nonpulsing Neutron Star | LMNS | 2222 |
| GX 9+9 | Nonpulsing Neutron Star | LMNS | 2066 |
| GX 3+1 | Nonpulsing Neutron Star | LMNS, Burster | 1862 |
| GX 5–1 | Nonpulsing Neutron Star | LMNS | 2659 |
| GX 9+1 | Nonpulsing Neutron Star | LMNS | 2618 |
| GX 13+1 | Nonpulsing Neutron Star | LMNS | 2082 |
| GX 17+2 | Nonpulsing Neutron Star | LMNS, Burster | 2134 |
| Ser X-1 | Nonpulsing Neutron Star | LMNS, Burster | 1863 |
| HETE J1900.1–2455 | Nonpulsing Neutron Star | LMNS, Burster | 1031 |
| Aql X-1 | Nonpulsing Neutron Star | LMNS, Burster | 274 |
| 4U1916–053 | Nonpulsing Neutron Star | LMNS, Burster | 565 |
| Cyg X-2 | Nonpulsing Neutron Star | LMNS | 1446 |
| SMC X-1 | Pulsar | HMNS | 978 |
| LMC X-4 | Pulsar | HMNS | 192 |
| 1A0535+262 | Pulsar | HMNS | 124 |
| Vela X-1 | Pulsar | HMNS | 686 |
| GRO J1008–57 | Pulsar | HMNS | 233 |
| Cen X-3 | Pulsar | HMNS | 1187 |
| GX 301–2 | Pulsar | HMNS | 192 |
| 4U1538–52 | Pulsar | HMNS | 193 |
| 4U1626–67 | Pulsar | LMNS | 1202 |
| Her X-1 | Pulsar | IMNS | 366 |
| OAO 1657 | Pulsar | HMNS | 157 |
| 4U1822–37 | Pulsar | LMNS | 919 |
Note. The classifications for each of these sources are from Liu et al. (2001), Liu et al. (2006), Liu et al. (2007), Shrader et al. (2010), Sreehari et al. (2019), and Torres et al. (2020).
Download table as: ASCIITypeset image
2.2. Subsampling of Observations
In our selection of data points, observations that are less bright are inherently less likely to be included. Because XRB systems of the same type can exhibit considerable variability in terms of which regions they occupy in CCI diagrams (Figure 3), this bias in data selection can be a limitation. We address this by subsampling where the probability that a particular observation is included in the training set is inversely proportional to the total number of observations of its system in the entire training set. An additional motivation for subsampling the data is for a computational reason: Gaussian process models can be particularly computationally expensive due to the inversion of a large matrix. The time required to perform this matrix inversion scales with O(N3), where N is the number of data points in the data set.
We run the subsampling algorithm 10 times to create 10 independent subsets of the data on which we can run our algorithms. The histograms in Figure 5 show the number of observations between various systems before subsampling and five examples of the distribution after subsampling. For each independent run, we sample 20% of the training data without replacement, resulting in a data set of 10,314 observations.
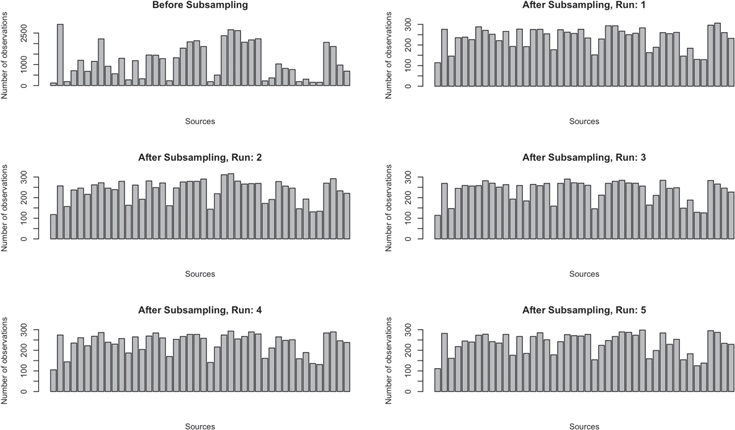
Figure 5. Distribution of the number of observations per source and five examples of distributions after subsampling. These were used to test BGP runs. These and an additional five subsamples (Shown in Figure A2) were used to test the KNN and SVM runs.
Download figure:
Standard image High-resolution image3. Classification Algorithms
In this paper, we compare a BGP (Williams & Barber 1998) method similar to that used in GP15, K-Nearest Neighbors (KNN; Altman 1992), and Support Vector Machines (SVM; Cortes & Vapnik 1995) in order to classify XRBs. For each algorithm, we present the predictions for each compact object where the predicted class of an XRB is the class with the maximum estimated probability. We evaluate each algorithm in terms of its predictive accuracy for classifying XRBs in the MAXI/GSC data set. Each algorithm is described in more detail in Sections 3.1, 3.2, and 3.3.
3.1. Bayesian Gaussian Process
BGP methods have been extensively used in ML for the classification and quantification of prediction uncertainty (Rasmussen & Williams 2005). In our work, we are using the BGP described in Williams & Barber (1998) as implemented in the R library Kernlab (Karatzoglou et al. 2004).
To use a BGP to solve our classification problem, we must choose a covariance kernel. In ML, capturing the similarity between data points is essential; on a basic level, we assume that points with inputs
x
that are close are likely to have similar target
y
values. The covariance function determines how this proximity or similarity is defined, and in this paper, we consider squared-exponential (i.e., Gaussian), Laplacian, and ANOVA radial basis function kernels as implemented in Karatzoglou et al. (2004). All three kernels are variants of radial basis functions, meaning that they are both stationary and isotropic kernels. Stationary kernels are invariant to translations in the input space and are a function of 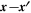 . If a kernel is also isotropic, it is more specifically a function of
. If a kernel is also isotropic, it is more specifically a function of 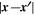 , making it invariant to rigid motions (Rasmussen & Williams 2005). We explicitly define the Gaussian and Laplacian Kernels below:
, making it invariant to rigid motions (Rasmussen & Williams 2005). We explicitly define the Gaussian and Laplacian Kernels below:
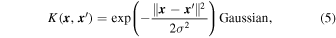
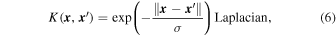
where 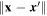 refers to the Euclidean distance (i.e., the two-norm) between two inputs
x
and
refers to the Euclidean distance (i.e., the two-norm) between two inputs
x
and  , σ is the characteristic length scale. To see a full derivation of the ANOVA kernel, please refer to Hofmann et al. (2008). In Section 4.2.2, we discuss how we compare and select from these three kernels for our specific classification problem.
, σ is the characteristic length scale. To see a full derivation of the ANOVA kernel, please refer to Hofmann et al. (2008). In Section 4.2.2, we discuss how we compare and select from these three kernels for our specific classification problem.
We determine the median probability of belonging to a certain class and estimate the errors in our BGP model by undertaking five independent runs of the best BGP model (Table A1) as described further in Section 4.3. Although we did this for 10 runs for each of our other models, computational costs limited us to 5 runs for the BGP. Table A1 lists the median and standard deviation (SD) from the five runs.
3.2. K-nearest Neighbors
A simpler ML algorithm called KNN (Altman 1992) is also used to predict XRB classifications. To implement our KNN algorithm, we customized code from the R caret package (Kuhn 2008) and the R class package (Venables & Ripley 2002). For any given input CCI data point, the KNN model first calculates the Euclidean distance between that data point and every other point in the training set. Certain variables might have an unusually large impact on this distance because their magnitude is larger without normalization. For example, the relative intensity spans a larger range of values than SCs and HCs, meaning that any distances along the SCs and HCs could be overshadowed by distances along the relative intensity. To adjust for this, we normalized the data set by the average of the top 0.01% of the counts before we began. Normalizing the training data has been shown to improve the KNN algorithm’s predictive accuracy dramatically (Hastie et al. 2001; Piryonesi & El-Diraby 2020).
After calculating the distances, we find the k data points closest to the input point p, which are the k-nearest neighbors. Then, we classify the point p based on the classifications of those neighbors. For example, if the majority of the k closest data points are labeled BH, then we classify the point as a BH. In Figure 6, KNN for a simple 2D case is illustrated where the two classes are BHs and NPNSs. Here, k = 5 and for the unknown point p, 60% of the k-nearest neighbors are NPNSs while 40% are BHs. Thus, the source has a 60% probability of being an NPNS and a 40% probability of being a BH.
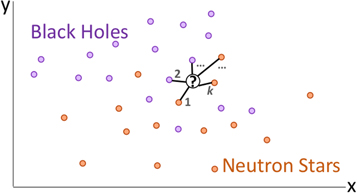
Figure 6. A schematic depicting KNN for BHs and NPNSs in two dimensions. For an unclassified source in the center, the model calculates the Euclidean distance between that point and every other data point. Then the k closest points to the unclassified source are used to predict the class. In this case, 60% of the KNNs are NPNSs while 40% are BHs. Thus, the source has a 60% probability of containing an NPNS and a 40% probability of containing a BH.
Download figure:
Standard image High-resolution imageWe choose k with a cross-validation procedure described in Section 4.2. After choosing k, we determine the median probability of belonging to a certain class and estimate the errors in our KNN model by undertaking 10 independent runs. Independence is achieved by generating a different subsample for each run (see Figure 5). Table A2 lists the median and SD from the 10 runs.
3.3. Support Vector Machines
Finally, we compare the use of the SVM (Cortes & Vapnik 1995) algorithm to make predictions on the compact object type of an XRB. To implement our SVM algorithm, we customized code from the LIBSVM library (Chang & Lin 2011). In an SVM, given the input and output data for each source, the goal is to find the hyperplane that creates the largest separation between the three classes of data. This is most clearly explained by examining a simple two-dimensional example.
Consider Figure 7(a), where data points are graphed with respect to variables x and y and colored purple or orange depending on whether they belong to the BH or NPNS class. Given these inputs, a linear SVM model would calculate the two-dimensional line that provides the largest possible separation between the two classes. In this case, the points border the two dotted lines and are a distance D apart. The separator between the two classes is the solid line between them. New points are classified based on their location with respect to this line. Note that to create this model, only the points near the boundary determine the location of the separator. Thus, points far away from the boundary could be removed from the training set and the resulting model would be identical.
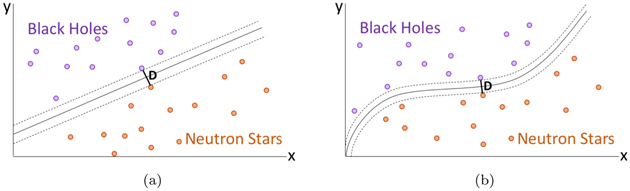
Figure 7. Simple representations for SVM. Panel (a) illustrates how a linear SVM finds the line that creates the largest separation possible between two classes of data, BHs and NPNSs. Panel (b) extends this to the nonlinear SVM, which uses the “kernel trick” to project the points into more dimensions, resulting in a nonlinear curve.
Download figure:
Standard image High-resolution imageHowever, this method has the obvious problem that the points may not always be linearly separable. To resolve this, a nonlinear SVM model uses a method known as the “kernel trick” where the points are projected into a space with even more dimensions, allowing the separator line to become a nonlinear curve. An example of this can be seen in Figure 7(b), where a nonlinear curve separates the BHs from NPNSs.
In higher dimensions, the logic is similar: the points are graphed in an n-dimensional space, and the optimal (n – 1)-dimensional dividing surface is then calculated. In the case of a linear SVM, this is a linear hyperplane; in the case of a nonlinear SVM, which we will use here, this is a nonlinear surface.
We computed both the probability of belonging to a class and error estimates. SVMs can produce class probabilities as outputs by fitting a sigmoid function
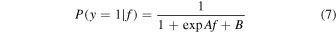
to the decision values f of the binary SVM classifiers, where A and B are estimated by minimizing the negative log-likelihood function. For this multiclass case, all three binary classifier probability outputs can be combined as described in Wu et al. (2009). This method is equivalent to fitting a logistic regression model to the estimated decision values (Karatzoglou et al.2006).
We determine the median probability of belonging to a certain class and estimate the errors in our SVM model by undertaking 10 independent runs. Independence is achieved by generating a different subsample for each run (see Figure 5). Table A3 lists the median and SD from the 10 runs.
4. Data Analysis
We use the sources from MAXI/GSC that meet our statistical significance criteria in Section 2.1. We use a 3D representation of data as introduced by VB13 to test the three ML techniques described in Section 3.
4.1. Input Representation
For each example in our training data set, the input vector consists of the coordinates in the CCI diagram and the output vector is the class (1 = BH, 2 = NPNS, or 3 = pulsar). The model is trained with these examples and asked to predict the probability that the input vector belongs to each of the classes. The output vector thus takes the form of Ypred = (0.12, 0.73, 0.15) for an example that has a 12%, 73%, and 15% probability of belonging to the BH, NPNS, and pulsar classes, respectively.
For the MAXI data set, these examples can be described as two-tuple (Xtrain, Ytrain), where Xtrain is the Ntrain by 3 matrix and Ytrain is the classification corresponding to the compact object type 1, 2, or 3. Our inputs can thus be represented as
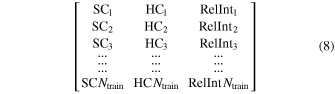
where SC1 stands for the soft color, HC1 stands for the hard color, and RelInt1 stands for the relative intensity of the first data point. The output Ytrain is a vector of length N, where N refers to the number of statistically significant data points in the training set. For a prediction for a single data point of an unclassified system, the ML algorithms use three features (SC, HC, and RelInt). Thus, for each row of SC, HC, and RelInt values in Equation (8), the ML models output a probability distribution across the BH, NPNS, pulsar classes. All predictions belonging to the observations for a particular source are then aggregated to generate a mean probability distribution per source as described in Section 4.3. Thus, for an XRB source with M observations, the number of features used to compute the overall probability distribution is 3 × M.
To ensure each model generalizes to XRB examples it has never seen before, we use a cross-validation method described in Section 4.2. This method checks whether the model can be applied to predict out-of-sample data rather than only being capable of memorizing and reproducing the input training set.
4.2. Cross-validation and Model Hyperparameters
A fundamental challenge in ML is that algorithms must perform well on novel, previously unseen inputs—not just examples on which the model was trained (Goodfellow et al. 2016). Being able to perform well on novel, previously unseen inputs is often referred to as generalization.
To estimate the ability of each ML algorithm to generalize to out-of-sample data, we use a cross-validation procedure. At each iteration of the procedure, we remove the CCI points corresponding to a particular source and use the remaining sources as training data, which comprises between 97% and 98% of the entire data set depending on the number of observations belonging to the removed source. Then, we predict the classification of the left-out source. We iterate this procedure for all of the sources in the data set, and the total number of correct classifications out of the 44 sources is indicative of the predictive accuracy on out-of-sample data. This cross-validation procedure is similar to k-fold cross-validation except that the data set is chunked based on the sources, as opposed to k equally sized chunks typically used in cross-validation. Chunking the data by source is more realistic because the ML algorithms will ultimately be used to predict the classification of a new source that the algorithms were not trained on.
4.2.1. BGP Parameter Tuning
During this cross-validation process, we tune the hyperparameters of the various ML architectures. Each architecture has different hyperparameters that can be tuned, which potentially decrease generalization error and thereby improve model performance. Some of these hyperparameters are specifically designed to minimize generalization error and prevent the ML model from overfitting to the training data. Methods that prevent overfitting are called regularization methods, and we will use cross-validation to optimize some of these regularization parameters.
For the BGP cross-validation, we compared the performance of three different covariance kernels (Gaussian, Laplacian, and ANOVA radial basis function kernels). The three kernels are explicitly defined in Section 3.1.
For all three kernels, the adjustable parameter σ significantly affects the performance of the kernel and serves as a regularization parameter. We set the BGP to use automatic sigma estimation as implemented in Karatzoglou et al. (2004). Although the Gaussian and Laplacian kernels are closely related, the Laplacian kernel loses the square norm and is less sensitive to changes in σ. The ANOVA kernel has been shown to work particularly well for multidimensional regression problems (Stitson et al. 1999), which we hoped might be promising for this multidimensional classification problem.
As illustrated in Table 2, the Gaussian and Laplacian kernels have the highest predictive accuracy, with 81.8% of sources correctly classified whereas the ANOVA kernel only predicted 29.6% of sources correctly. The ANOVA predicted nearly every source to belong to the BH class, which negates the high predictive accuracy of BH sources compared to NPNSs and pulsars. Although the Laplacian and Gaussian kernels provide the same number of correct predictions (81.8%), the Gaussian kernel takes four times as long to run. Thus, we chose the Laplacian kernel for our final model because it is both the most computationally efficient and provides the best performance on the cross-validation. We ran our final model five times and computed the median and SD across those five runs (Table A1).
Table 2. BGP Cross-validation Results
| Model Parameters | Percentage Classified as X per Source Type Xa | Overall Accuracy | |||
|---|---|---|---|---|---|
| Kernel | Time (hr) | BH | NPNS | Pulsar | Total |
| ANOVA | 101.4 | 100.00% | 5.00% b | 0.00% b | 29.55% |
| Laplace | 32.7 | 41.67% | 95.0% | 100.00% | 81.82% |
| Gaussian | 132.6 | 41.67% | 95.0% | 100.00% | 81.82% |
Notes. We determined the model accuracy across different kernels by implementing each one and counting the number of correct classifications for each source type.
a Here X can be a BH, NPNS, or pulsar. For example, for the BH column, the percentage listed is the percentage of BH sources that are classified as BHs. For the NPNS column, the percentage listed is the percentage of NPNS sources that are classified as NPNSs, etc. b Only 5% of NPNSs are classified as NPNSs and 0% of pulsars are classified as pulsars because the algorithm classified nearly all sources as BHs.Download table as: ASCIITypeset image
4.2.2. KNN Hyperparameter Tuning
For the cross-validation procedure, we chose to iterate through 49 different values for k. We examined the range k = 2 through k = 50 as these values are not so small that it leads to unstable decision boundaries but also not so large that it becomes computationally expensive.
As illustrated in Table 3, we found that for values of k = 17, 18, 22, 24, 44, and 45−50, 81.8% of sources are correctly classified. For these values of k, we found that k = 24 provides predictions with the highest probabilities of belonging to the correct class across all three source types. Thus, we chose k = 24 for our final model. We ran our final model 10 times and computed the median and SD across those 10 runs (Table A2).
Table 3. KNN Cross-validation Results
| Model Parameters | Percentage Classified as X per Source Type Xa | Overall Accuracy | |||
|---|---|---|---|---|---|
| K values | Time (minutes) | BH | NPNS | Pulsar | Total |
| 2–16 | ∼10 | 41.67% b | 90.00% | 100.00% | 79.54% |
| 17–18 | ∼10 | 50.0% | 90.00% | 100.00% | 81.82% |
| 19–21 | ∼10 | 41.67% | 90.00% | 100.00% | 79.54% |
| 22 | ∼10 | 50.0% | 90.00% | 100.00% | 81.82% |
| 23 | ∼10 | 41.67% | 90.00% | 100.00% | 79.54% |
| 24 | ∼10 | 50.0% | 90.00% | 100.00% | 81.82% |
| 25–43 | ∼10 | 41.67% | 90.00% | 100.00% | 79.54% |
| 44 | ∼10 | 41.67% | 95.00% | 100.00% | 81.82% |
| 45 | ∼10 | 41.67% | 85.71% | 100.00% | 79.54% |
| 45–50 | ∼10 | 41.67% | 95.00% | 100.00% | 81.82% |
Notes. We determined the model accuracy across values of k by iteratively trying values from 2 to 50 and counting the number of correct classifications per source class.
a Here X can be a BH, NPNS, or pulsar. For example, for the BH column, the percentage listed is the percentage of BH sources that are classified as BHs. For the NPNS column, the percentage listed is the percentage of NPNS sources that are classified as NPNSs, etc. b For the BHs that are not correctly classified, the algorithm commonly predicts these sources to be NPNSs instead.Download table as: ASCIITypeset image
4.2.3. SVM Hyperparameter Tuning
For the SVM cross-validation, we chose to sample 100 values across the parameter space of the hyperparameters gamma and cost (C). Because these parameters span a large range of possible ideal values (2−15–23 for gamma, Chang & Lin 2011; 2−15–25 for C, Chang & Lin 2011), they required an efficient sampling method. We implemented Latin hypercube sampling (Carnell 2020), which is a statistical technique that achieves near-random sampling across parameters (Stein 1987) and is commonly used for sampling large parameter spaces.
Gamma can be thought of as defining the radius of influence of the support vectors. When gamma is very small, the model is too constrained and cannot capture the features or complexity in the data. However, making gamma too large corresponds to the radius of the support vectors only including the support vectors themselves, resulting in overfitting on the training data and large generalization errors.
The other parameter we simultaneously optimized was C, which is a regularization term in the Lagrange formulation of SVMs. C presents a trade-off between the correct classification of training examples and against maximizing the margin of the decision function. Increasing C means that a smaller margin will be deemed acceptable and result in better classification of training points. Lower values of C will create a larger margin and a simpler decision function, which may prevent overfitting but also decreases training accuracy. In this way, C can prevent the SVM model from overfitting, decrease the generalization error, and serve as a regularization parameter.
The best-performing hyperparameter combinations are summarized in Table 4, and the performance across all 100 samples is illustrated in Figure 8. Ultimately, the best-performing models with ∼86.4% accuracy had values of C between ∼0.06 and ∼0.1 and for gamma between ∼0.57 and ∼2.3. For these values of gamma and C, we found that C = 0.655 and gamma = 0.585 provide predictions with the highest probabilities of belonging to the correct class across all three source types. Thus, we chose those hyperparameter values for our final model. We ran our final model 10 times and computed the median and SD across those 10 runs (Table A3).
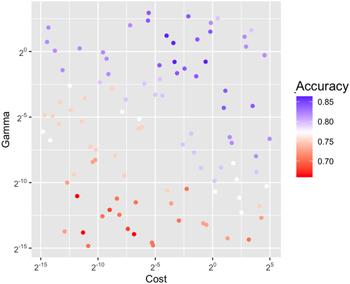
Figure 8. Latin hypercube sampling across values of Gamma and C. We ran 100 different configurations of gamma and C for our SVM model using Latin hypercube sampling. As both gamma and C increase, the number of correct classifications across sources (accuracy) increases up until a certain point (gamma ∼21, cost ∼2−3).
Download figure:
Standard image High-resolution imageTable 4. SVM Cross-validation Results
| Model Parameters | Percentage Classified as X per Source Type Xa | Overall Accuracy | ||||
|---|---|---|---|---|---|---|
| C | Gamma | Time (minutes) | BH | NPNS | Pulsar | Total |
| 0.040 | 0.484 | ∼20 | 50.00% | 95.00% | 100.00% | 84.09% |
| 0.116 | 0.318 | ∼20 | 50.00% | 95.00% | 100.00% | 84.09% |
| 0.184 | 0.406 | ∼20 | 50.00% | 95.00% | 100.00% | 84.09% |
| 0.231 | 6.437 | ∼20 | 50.00% | 95.00% | 100.00% | 84.09% |
| 0.371 | 0.270 | ∼20 | 50.00% | 95.00% | 100.00% | 84.09% |
| 0.397 | 1.898 | ∼20 | 50.00% | 95.00% | 100.00% | 84.09% |
| 0.870 | 2.859 | ∼20 | 50.00% | 95.00% | 100.00% | 84.09% |
| 1.969 | 0.051 | ∼20 | 50.00% | 95.00% | 100.00% | 84.09% |
| 2.162 | 0.126 | ∼20 | 50.00% | 95.00% | 100.00% | 84.09% |
| 0.020 | 5.141 | ∼20 | 58.33% | 90.00% | 100.00% | 84.09% |
| 0.021 | 7.729 | ∼20 | 58.33% | 90.00% | 100.00% | 84.09% |
| 0.062 | 2.314 | ∼20 | 58.33% | 95.00% | 100.00% | 86.36% |
| 0.093 | 1.572 | ∼20 | 58.33% | 95.00% | 100.00% | 86.36% |
| 0.100 | 0.579 | ∼20 | 58.33% | 95.00% | 100.00% | 86.36% |
| 0.655 | 0.585 | ∼20 | 58.33% | 95.00% | 100.00% | 86.36% |
Notes. To compute how the model accuracy changed based on values of the hyperparameters C and gamma, we implemented Latin hypercube sampling across the parameter space (C = 2−15–25, gamma = 2−15–23). The 15 best-performing combinations of C and gamma are summarized here.
a Here X can be a BH, NPNS, or pulsar. For example, for the BH column, the percentage listed is the percentage of BH sources that are classified as BHs. For the NPNS column, the percentage listed is the percentage of NPNS sources that are classified as NPNSs, etc.Download table as: ASCIITypeset image
4.3. Aggregation of Predictions
Because the ML algorithms treat each observation independently and compute their predicted probability distribution, we aggregate the predictions per source to compute an overall probability distribution. Specifically, for a given XRB system with M observations, we compute the overall probability distribution and corresponding SDs after performing the cross-validation by taking the following two steps:
- 1.First, we compute the mean probability distribution across the M observations belonging to that system.
- 2.We then estimate the errors in our models by undertaking 10 independent runs (5 for the BGP due to computational constraints). Independence is achieved by generating a different subsample for each run (see Figure 5). Across those 10 independent runs, we repeat step 1, aggregate those results, and compute the median and sample SD across the 10 probability distributions.
Resampling data to estimate errors has a long history in statistics through methods such as bootstrapping (Efron & Tibshirani 1993) and has also been shown to reliably produce error estimates when applied to ML algorithms (Stracuzzi et al.2017).
In this way, we aggregate the predictions to get a median and SD for each XRB source in Table 1.
4.4. Indeterminate Classifications
For some of the XRB sources, the median probability of belonging to two or more classes is equal (within 1σ). In this case, we chose to assign the sources an indeterminate classification because the algorithms cannot distinguish them within the error.
5. Results of ML Classification
In Figure 9, we summarize the predictive accuracy for each algorithm and XRB class in confusion matrices, which were generated from the median predictions across all runs. 9 All three methods have a relatively high predictive accuracy on average but vary considerably across XRB classes. The KNN performs best with 84.1% of sources correctly classified compared to 81.8% for both the BGP and the SVM. Figures 10–12 depict the probabilities from the 44 source cross-validation for XRB sources derived from the three ML models. Purple indicates the probability of belonging to the class of BHs, orange indicates NPNSs, and green indicates pulsars. All three methods incorrectly classify a large fraction (∼50%–58%) of the BH sources.
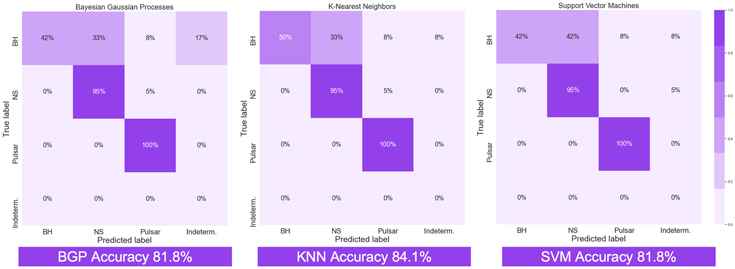
Figure 9. Accuracy of predictions per class of XRBs for each ML model. “Indeterm.” stands for indeterminate classifications where there is an equal probability (within error) of belonging to two classes. The KNN model has the highest predictive accuracy by predicting 84.1% of sources in the cross-validation correctly. The BGP and SVM follow with 81.8% of cross-validation sources predicted correctly (Figures 10, 11, 12). All three models incorrectly classify a large fraction (∼50–58%) of the BH sources.
Download figure:
Standard image High-resolution image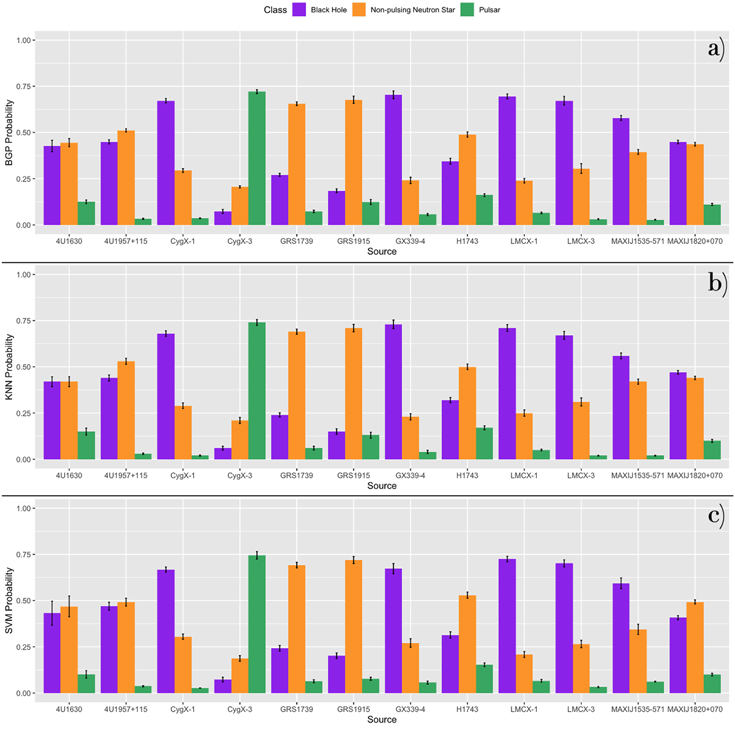
Figure 10. Probabilities of the 44 source cross-validation for BH sources derived from ML models. Purple indicates the probability of belonging to the class of BHs, orange indicates NPNSs, and green indicates pulsars. The median probability across 10 runs and the SD across runs are plotted.
Download figure:
Standard image High-resolution image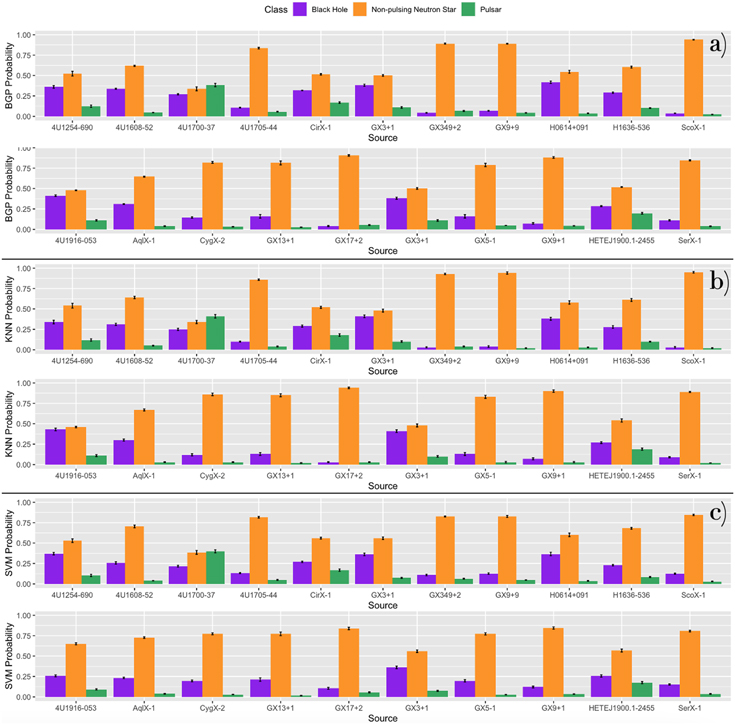
Figure 11. The probabilities of the 44 source cross-validation for NPNS sources derived from all three ML models. Purple indicates the probability of belonging to the class of BHs, orange indicates NPNSs, and green indicates pulsars. The median probability across 10 runs and the SD across runs are plotted.
Download figure:
Standard image High-resolution image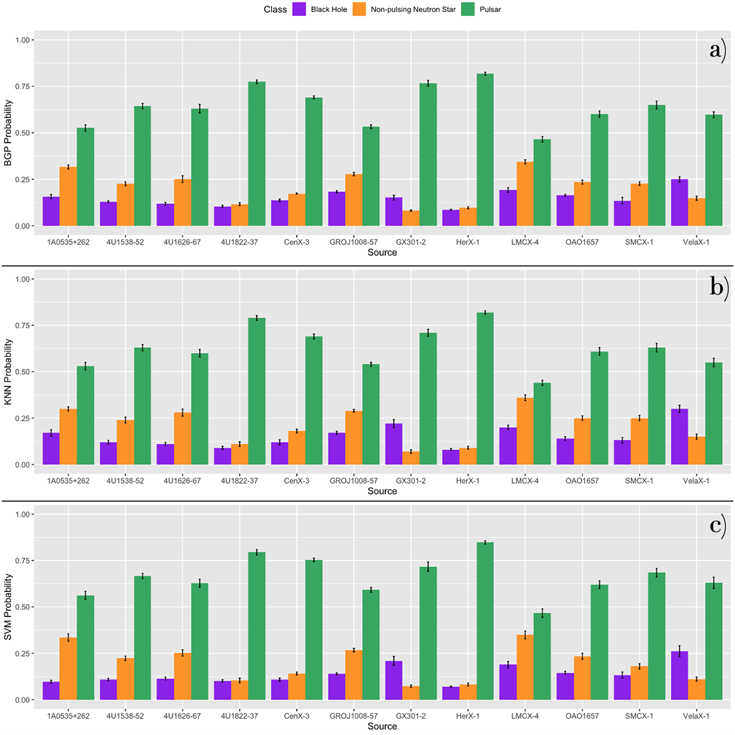
Figure 12. The probabilities of the 44 source cross-validation for pulsar sources derived from all three ML models. Purple indicates the probability of belonging to the class of BHs, orange indicates NPNSs, and green indicates pulsars. The median probability across 10 runs and the SD across runs are plotted.
Download figure:
Standard image High-resolution imageBased on these results, we can use our prior knowledge to compute the conditional probabilities that a source is a specific type of compact object given the prediction (often also referred to as precision). For example, we can compute the probability that a source’s true classification, trueclass, is an NPNS given that our BGP model predicts it to be an NPNS in the following way:

where predclass is the model predicted classification, 23 of our sources are predicted to be NPNSs, and only 19 both have a true classification and predicted classification as an NPNS. Thus, the BGP conditional probability that a source predicted to be an NPNS truly is an NPNS is 0.83. In the exact same way, we computed these BGP model conditional probabilities for BHs and pulsars and for all three classes using KNN and SVM as presented in Table 5.
Table 5. Conditional Probabilities
| BGP Conditional | Probability |
|---|---|
| P(trueclass = BH ∣predclass = BH) | 100.0% |
| P(trueclass = NPNS ∣predclass = NPNS) | 82.6% |
| P(trueclass = Pulsar ∣predclass = Pulsar) | 85.7% |
| KNN Conditional | Probability |
| P(trueclass = BH ∣predclass = BH) | 100.0% |
| P(trueclass = NPNS ∣predclass = NPNS) | 82.6% |
| P(trueclass = Pulsar ∣predclass = Pulsar) | 85.7% |
| SVM Conditional | Probability |
| P(trueclass = BH ∣predclass = BH) | 100.0% |
| P(trueclass = NPNS ∣predclass = NPNS) | 79.2% |
| P(trueclass = Pulsar ∣predclass = Pulsar) | 92.3% |
Note. We determined the conditional probabilities for each model and source type using Equation (9).
Download table as: ASCIITypeset image
In all three methods, the primary misclassification of BHs is as NPNSs. The difficulty of separating BHs from a subclass of NPNSs called bursters was already noted by GP15. As Figure 1 illustrates, both BHs and bursters spend significant time in quiescence. In Figure 13, we plot the four BHs that are misclassified as NPNSs together with the bursters. It is clear that bursters and BHs are distinct in location during their “on” or “burst” states, while there is significant overlap during quiescence. One possibility to mitigate this effect is to put in an intensity cutoff for bursters and/or BHs in the training set. We tested this approach for bursters and describe the results in Section 5.1. A more universal means of mitigating this effect would be to include a fourth dimension that takes into account the temporal variability of the sources. From the examples in Figure 1, it appears that BHs spend more time in quiescence with “on” states that last longer than the durations of the “bursts” of bursters. However, a more rigorous definition of variability may be necessary. Both of these methods are currently being tested and will be presented in a future paper.
Figure 13. The four BHs misclassified as bursters in purple and bursters in orange. An animation of this figure is available. In the animation, the figure rotates from 0°to 360°to illustrate the spatial patterns in the data. The real-time duration of the animation is 36 s. In the animation, we observe that the four misclassified BHs are separated from the burster sources at higher relative intensities but significantly overlap at lower relative intensities.
(An animation of this figure is available.)
Download figure:
Video Standard image High-resolution imageAll three models misclassify Cyg X-3 as a pulsar. In Figure 14 we show Cyg X-3 in red, along with BHs (excluding Cyg X-3) in purple, and all pulsars in green. It is clear that Cyg X-3 has little overlap with the other BHs in our sample but does have some overlap with pulsars. Cyg X-3 is an unusual source, showing ultra-high-energy gamma-rays and radio flares, during which it becomes the brightest radio source in the Milky Way (Koljonen et al. 2018).
Figure 14. The BH Cyg X-3 in red; BHs in training set excluding Cyg X-3 in purple; all pulsars in the training set in green. In the animation, the figure rotates from 0° to 360° to illustrate the spatial patterns in the data. The real-time duration of the animation is 36 s. In the animation, we observe that BH Cyg X-3 has little spatial overlap with other BHs in our sample and instead occupies a similar region of CCI space with the pulsars at HC ∼0.6–1, SC ∼0.6–0.8, and RelInt ∼0.0–0.5.
(An animation of this figure is available.)
Download figure:
Video Standard image High-resolution imageAll three models do well in classifying NPNSs, with one exception: 4U1700–37 is classified as a pulsar (or as indeterminate 10 by the SVM). In Figure 15, we show 4U1700–37 in black, along with all NPNSs in orange, and all pulsars in green. It is clear that while 4U1700–37 does share some space with NPNS, the majority of its data points overlap with pulsars. While no pulses have been detected from 4U1700–37, several authors have noted that its temporal and spectral characteristics are very similar to highly magnetized HMXBs (Boroson et al. 2003; Islam & Paul 2016; Martinez-Chicharro et al. 2018).
Figure 15. The NPNS 4U1700–37 in black, other NPNS sources in the training set in orange, and all pulsar sources in the training set in green. In the animation, the figure rotates from 0° to 360° to illustrate the spatial patterns in the data. The real-time duration of the animation is 36 s. In the animation, we observe that 4U1700–37 remains in quiescence and has some overlap with other NPNS sources. However, the majority of its data points overlap with pulsars in our training set.
(An animation of this figure is available.)
Download figure:
Video Standard image High-resolution imageAll three models have no difficulty in correctly classifying all pulsars (Figure 12).
5.1. BHs Misclassified as NPNSs: Quiescence Analysis
To examine the role of the quiescent observations in the misclassification of BHs as NPNSs, we ran two independent analyses where we included only the burster observations when sources were in an “on” or “burst” state and all observations for other source types. In these two analyses, we changed how we determined which points were considered in quiescence versus in a “burst” state.
In the first analysis, we applied a uniform cutoff where all points with a relative intensity below 0.4 were removed from burster sources in the training set. The number 0.4 was chosen because most “on” or “burst” observations fall above this threshold. We found that this uniform cutoff significantly increased the BH classification accuracy, leading to twice as many BHs being classified correctly for all three ML methods. In addition, pulsars and NPNSs are correctly classified with rates of 100% and 90%, respectively.
In the second analysis, we changed the exact cutoff based on each burster source’s unique variation in relative intensity. In particular, we computed the mean and SD of the relative intensity for each burster source. Then, we define the cutoff as
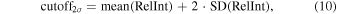
where RelInt is the relative intensity. We assume all points below this cutoff to be in quiescence and remove them from the training set. Similar to the 0.4 cutoff analysis, we find that this cutoff2σ method also leads to twice as many BHs being classified correctly for all three ML methods. Pulsars and NPNSs are correctly classified with rates of 100% and 85%, respectively. Overall, the results across these two quiescence analyses support our hypothesis that significant parameter overlap during the quiescence of BHs and NPNS could play a role in the misclassifications we observe for BHs.
5.2. Probability Thresholds
The accuracy of each of the ML algorithms can also be affected by the choice of a specific probability threshold. In the results reported throughout this paper, the class with the largest probability is assigned as the predicted class, regardless of the exact value of the largest probability. However, in some ML applications, a probability threshold is chosen instead to assign the predicted class. We investigated how choosing a probability threshold rather than choosing the class with the largest predicted probability would affect the accuracy of our models by using Receiver Operator Characteristic (ROC) curves.
ROC curves plot the True Positive Rate (TPR) and False Positive Rate (FPR) for various probability thresholds. The TPR and FPR are defined in the following way:
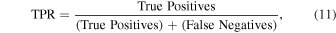
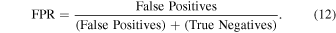
ROC curves can allow us to choose a threshold where the TPR → 1 while the FPR → 0. For a perfect classifier (TPR = 1, FPR = 0), the “elbow” of the ROC curve tightly fits in the upper-left corner. This perfect classifier is plotted in each of the subplots of Figure A1 along with the ROC curves of the ML methods. We can also compute the area under the curve (AUC) for each of these ROC curves. AUC is a threshold-sensitive measure of model accuracy. A perfect classifier has an AUC = 1, whereas a completely random classifier would have an AUC = 0.5.
We listed the AUC values for each XRB class and each ML model in Figure A1. The AUC values for column 3 are the highest, ranging from 0.97 to 0.98, meaning that all three algorithms are nearly perfect classifiers for pulsars. For NPNS, the SVM model outperforms the others with AUC = 0.9 compared to AUC = 0.88 for the KNN and BGP models. Across BHs, the differences between model accuracy for the methods are marginally smaller (BGP AUC = 0.86, SVM AUC = 0.86, KNN AUC = 0.85).
Users of our software may use these ROC curves to choose an appropriate threshold for their own specific purposes. If a user’s primary concern is reducing the FPR to zero, a higher-probability threshold could be chosen based on the ROC curves. For instance, say a user primarily wants to minimize BH false positives with the KNN method, Figure A1(g) indicates that a probability threshold of ∼0.40 would keep the FPR at zero while providing them with a TPR of ∼0.6. Depending on a user’s exact purposes, they may instead consider a few false positives acceptable and would prefer to increase the TPR. In that type of scenario, a lower-probability threshold may be more appropriate. Overall, these ROC curves allow users to choose a threshold that balances the FPR and TPR in a manner that is suitable for their own specific purposes.
6. Computational Efficiency
For a single full cross-validation run, the BGP requires ∼30 hr on the MIT Supercloud operated by the Lincoln Laboratory Supercomputing Center; both the KNN and SVM can run on a personal computer (MacBook Pro 2.5 GHz Intel Core i7) with KNN taking about ∼10 minutes for one run of the entire cross-validation set and SVM taking about ∼20 minutes.
7. Discussion and Conclusion
This paper compares three ML methods (BGP, KNN, and SVM) to test their feasibility for accurate classification of the nature of the compact object in XRBs. All three have relatively high predictive accuracy, ranging from 81.8% to 84.1% on average, with class-specific breakdowns as shown in Figure 9. In terms of predictive accuracy, the KNN model outperforms the SVM and BGP. The KNN model correctly predicts the classifications of 84.1% of sources compared to 81.8% for the SVM and BGP. These differences in predictive power primarily stem from differences in misclassifications or indeterminate classifications of BHs across methods.
In terms of computational efficiency, the KNN and SVM models outperform the BGP. Specifically, the BGP requires ∼30−130 hr on a supercomputer cluster whereas SVM and KNN can be run on a MacBook Pro (2.5 GHz Intel Core i7) within 10–120 minutes.
In a previous work (GP15), the largest number of sources misclassified were LMNS bursters, with only 33.3% correctly classified. In GP15, bursters were excluded from the training set and only used for validation. We found that by including bursters in the training set, we can achieve significant improvement where now 100.0% of bursters are correctly classified for the BGP, KNN, and SVM models. However, the similarity between BHs and bursters in quiescence leads to the misclassification of some BHs as bursters.
To improve the prediction accuracy of the BGP classification method compared to GP15, we also increased the sampling of the data from 10% to 20% and perform the 44 source cross-validation on the MIT Supercloud cluster. In future work, including larger samples of classified XRB sources for training could improve model performance and provide robust methods for classifying new sources, potentially even extragalactic sources from Chandra X-ray Observatory. In addition, these methods may also be applicable to cataclysmic variables in future studies. Adding dimensions to include other attributes that are easily available from the lightcurve data set we used (such as long-term temporal behavior), could also significantly increase the predictive accuracy.
This work suggests that applying ML methods to understand XRBs could potentially pave the way toward solutions to time-consuming problems, such as measuring compact object masses, determining luminosity and strengths of magnetic fields, and the spatial distribution of XRBs in galaxies. This research provides the astrophysics community with efficient tools to classify novel XRBs, accelerating our understanding of XRBs’ unique role in galaxy formation and evolution. We have made the software for all three methods publicly available on github. 11
7.1. Animations
We thank the anonymous referees for their detailed and constructive report, from which this manuscript greatly benefited. We thank Jonathan McDowell for his insightful knowledge of C, which was instrumental in resolving package installation errors. We also thank Matt Ashby for his constructive and invaluable feedback in the writing process. Further, we thank Vinay Kashyap, Aneta Siemiginowksa, and Josh Speagle for their statistical and machine-learning expertise that furthered the work. We thank Professor Alyssa Goodman for use of the FASRC Odyssey cluster supported by the FAS Division of Science Research Computing Group at Harvard University. We thank Adam Kraus and Andrew Vanderburg for use of the Texas Advanced Computing Center (TACC) at the University of Texas at Austin which provided HPC resources that have contributed to the research results reported within this paper. The authors also acknowledge the MIT SuperCloud and Lincoln Laboratory Supercomputing Center for providing HPC resources that have contributed to the research results reported within this paper.
The SAO REU program is funded in part by the National Science Foundation REU and Department of Defense ASSURE programs under NSF grant No. AST-1852268 and by the Smithsonian Institution. This material is based upon work supported by the National Science Foundation Graduate Research Fellowship under Grant No. 1745302. This research has made use of MAXI data provided by RIKEN, JAXA, and the MAXI team.
Software: R (R Core Team 2021), Kernlab (Karatzoglou et al. 2004), ggplot2 (Wickham 2016), LIBSVM library (Chang & Lin 2011), class package (Venables & Ripley 2002).
Appendix
In this appendix, we include tables listing the median probability distributions and corresponding standard deviations produced by each of the machine learning algorithms (Tables A1–A3). In addition, we provide a supplemental figure demonstrating model performance for various probability thresholds (Figure A1) and provide a figure showing the distributions of the number of observations after subsampling (Figure A2). More details on Figure A1 are provided in Section 5.2.
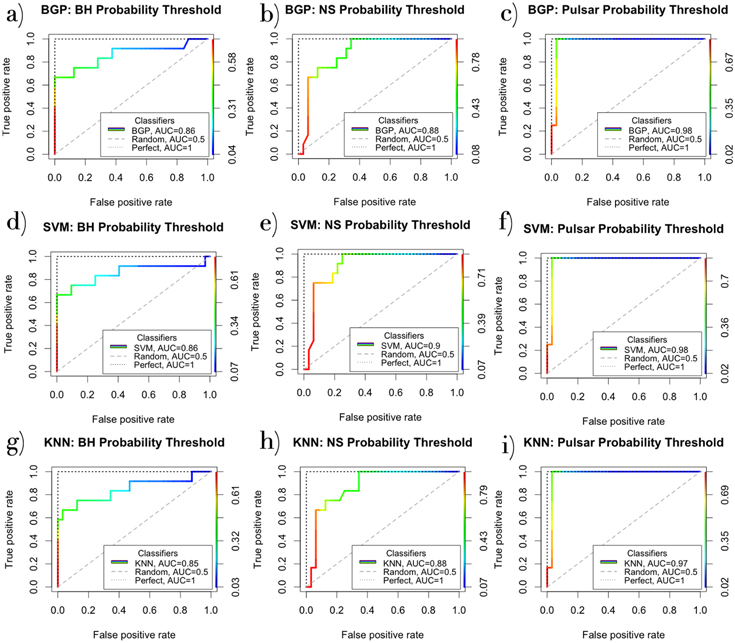
Figure A1. Receiver Operator Curves (ROC) for all three ML methods. Each column of subplots evaluates the performance of a single XRB class. Each row of subplots focuses on the performance of a single ML method across all three XRB classes. Column I (a, d, g): ROC curves for various BH probability thresholds across ML methods. Column II (b, e, h): ROC curves for various NPNS probability thresholds across ML methods. Column III (c, f, i): ROC curves for various pulsar probability thresholds across ML methods. In each subplot, the dotted line represents a perfect classifier (AUC = 1). The dashed line in each subplot represents a random classifier (AUC = 0.5). The rainbow lines represent our actual classifiers where the color corresponds to a specific probability threshold as indicated in the color bar on the right in each subplot.
Download figure:
Standard image High-resolution image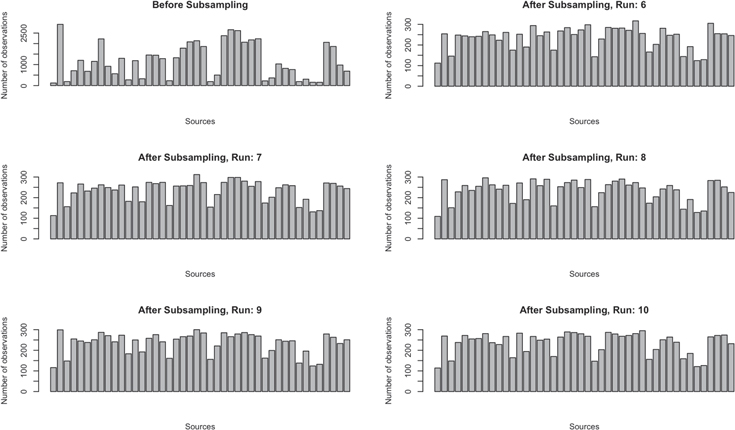
Figure A2. Distribution of the number of observations per source and five examples of distributions after subsampling. These and the additional five subsamples (shown in Figure 5) were used to test the KNN and SVM runs.
Download figure:
Standard image High-resolution imageTable A1. BGP Probabilities and Predictions for the Best Model (Kernel = Laplace)
| System | Prob(BH) a | SD b | Prob(NPNS) | SD | Prob(Pulsar) | SD | Pred. | Class | Correct? |
|---|---|---|---|---|---|---|---|---|---|
| LMC X-3 | 0.67 | 2.4 × 10−2 | 0.30 | 2.6 × 10−2 | 0.03 | 3.3 × 10−3 | BH | BH | Yes |
| LMC X-1 | 0.70 | 1.3 × 10−2 | 0.24 | 1.2 × 10−2 | 0.07 | 4.3 × 10−3 | BH | BH | Yes |
| MAXI J1535–571 | 0.58 | 1.3 × 10−2 | 0.40 | 1.3 × 10−2 | 0.03 | 2.0 × 10−3 | BH | BH | Yes |
| 4U1630–47 | 0.43 | 3.1 × 10−2 | 0.44 | 2.2 × 10−2 | 0.13 | 1.0 × 10−2 | BH or NPNS | BH | No |
| GX 339–4 | 0.70 | 2.1 × 10−2 | 0.24 | 1.7 × 10−2 | 0.06 | 6.2 × 10−3 | BH | BH | Yes |
| GRS 1739–278 | 0.27 | 8.3 × 10−3 | 0.66 | 1.0 × 10−2 | 0.07 | 7.0 × 10−3 | NPNS | BH | No |
| H1743–322 | 0.34 | 1.6 × 10−2 | 0.49 | 1.4 × 10−2 | 0.16 | 7.1 × 10−3 | NPNS | BH | No |
| MAXI J1820+070 | 0.45 | 1.0 × 10−2 | 0.44 | 1.0 × 10−2 | 0.11 | 6.0 × 10−3 | BH or NPNS | BH | No |
| GRS 1915 | 0.18 | 1.0 × 10−2 | 0.68 | 2.0 × 10−2 | 0.12 | 1.3 × 10−2 | NPNS | BH | No |
| Cyg X-1 | 0.67 | 1.2 × 10−2 | 0.29 | 1.0 × 10−2 | 0.04 | 1.8 × 10−3 | BH | BH | Yes |
| 4U1957+115 | 0.45 | 1.1 × 10−2 | 0.51 | 8.9 × 10−3 | 0.03 | 3.3 × 10−3 | NPNS | BH | No |
| Cyg X-3 | 0.07 | 1.1 × 10−2 | 0.21 | 5.7 × 10−3 | 0.72 | 1.1 × 10−2 | Pulsar | BH | No |
| H0614+091 | 0.42 | 1.5 × 10−2 | 0.54 | 1.8 × 10−2 | 0.04 | 3.0 × 10−3 | NPNS | NPNS | Yes |
| 4U1254–690 | 0.36 | 1.6 × 10−2 | 0.52 | 2.9 × 10−2 | 0.12 | 1.4 × 10−2 | NPNS | NPNS | Yes |
| Cir X-1 | 0.32 | 1.9 × 10−3 | 0.52 | 9.0 × 10−3 | 0.17 | 9.0 × 10−3 | NPNS | NPNS | Yes |
| 4U1608–52 | 0.34 | 7.1 × 10−3 | 0.62 | 6.6 × 10−3 | 0.05 | 3.4 × 10−3 | NPNS | NPNS | Yes |
| Sco X-1 | 0.04 | 2.4 × 10−3 | 0.94 | 3.4 × 10−3 | 0.02 | 1.8 × 10−3 | NPNS | NPNS | Yes |
| H1636–536 | 0.29 | 7.9 × 10−3 | 0.60 | 1.1 × 10−2 | 0.10 | 4.5 × 10−3 | NPNS | NPNS | Yes |
| 4U1700–37 | 0.27 | 6.6 × 10−3 | 0.34 | 2.4 × 10−2 | 0.38 | 2.0 × 10−2 | Pulsar | NPNS | No |
| GX 349+2 | 0.04 | 3.4 × 10−3 | 0.89 | 6.9 × 10−3 | 0.07 | 6.0 × 10−3 | NPNS | NPNS | Yes |
| 4U1705–44 | 0.11 | 5.3 × 10−3 | 0.84 | 8.7 × 10−3 | 0.06 | 3.5 × 10−3 | NPNS | NPNS | Yes |
| GX 9+9 | 0.07 | 3.9 × 10−3 | 0.89 | 4.4 × 10−3 | 0.04 | 1.8 × 10−3 | NPNS | NPNS | Yes |
| GX 3+1 | 0.38 | 1.2 × 10−2 | 0.50 | 1.1 × 10−2 | 0.11 | 1.0 × 10−2 | NPNS | NPNS | Yes |
| GX 5–1 | 0.16 | 2.0 × 10−2 | 0.79 | 2.0 × 10−2 | 0.05 | 1.4 × 10−3 | NPNS | NPNS | Yes |
| GX 9+1 | 0.07 | 9.1 × 10−3 | 0.88 | 9.6 × 10−3 | 0.04 | 1.3 × 10−3 | NPNS | NPNS | Yes |
| GX 13+1 | 0.16 | 2.2 × 10−2 | 0.81 | 2.3 × 10−2 | 0.03 | 2.2 × 10−3 | NPNS | NPNS | Yes |
| GX 17+2 | 0.04 | 5.5 × 10−3 | 0.91 | 9.4 × 10−3 | 0.05 | 5.1 × 10−3 | NPNS | NPNS | Yes |
| Ser X-1 | 0.11 | 6.9 × 10−3 | 0.85 | 6.7 × 10−3 | 0.04 | 3.7 × 10−3 | NPNS | NPNS | Yes |
| HETE J1900.1–2455 | 0.28 | 7.0 × 10−3 | 0.52 | 4.4 × 10−3 | 0.20 | 1.0 × 10−2 | NPNS | NPNS | Yes |
| Aql X-1 | 0.31 | 5.5 × 10−3 | 0.65 | 5.6 × 10−3 | 0.04 | 4.2 × 10−3 | NPNS | NPNS | Yes |
| 4U1916–053 | 0.41 | 1.0 × 10−2 | 0.48 | 3.9 × 10−3 | 0.11 | 9.1 × 10−3 | NPNS | NPNS | Yes |
| Cyg X-2 | 0.15 | 9.3 × 10−3 | 0.82 | 1.1 × 10−2 | 0.03 | 2.6 × 10−3 | NPNS | NPNS | Yes |
| SMC X-1 | 0.13 | 1.7 × 10−2 | 0.23 | 1.0 × 10−2 | 0.65 | 2.1 × 10−2 | Pulsar | Pulsar | Yes |
| LMC X-4 | 0.19 | 1.3 × 10−2 | 0.34 | 1.1 × 10−2 | 0.46 | 1.5 × 10−2 | Pulsar | Pulsar | Yes |
| 1A0535+262 | 0.16 | 1.1 × 10−2 | 0.32 | 1.1 × 10−2 | 0.53 | 1.7 × 10−2 | Pulsar | Pulsar | Yes |
| Vela X-1 | 0.25 | 1.5 × 10−2 | 0.15 | 1.1 × 10−2 | 0.60 | 1.6 × 10−2 | Pulsar | Pulsar | Yes |
| GRO J1008–57 | 0.18 | 5.8 × 10−3 | 0.28 | 8.6 × 10−3 | 0.53 | 9.7 × 10−3 | Pulsar | Pulsar | Yes |
| Cen X-3 | 0.14 | 6.7 × 10−3 | 0.17 | 3.1 × 10−3 | 0.69 | 7.3 × 10−3 | Pulsar | Pulsar | Yes |
| GX 301–2 | 0.15 | 1.3 × 10−2 | 0.08 | 4.3 × 10−3 | 0.77 | 1.5 × 10−2 | Pulsar | Pulsar | Yes |
| 4U1538–52 | 0.13 | 3.5 × 10−3 | 0.23 | 1.1 × 10−2 | 0.64 | 1.4 × 10−2 | Pulsar | Pulsar | Yes |
| 4U1626–67 | 0.12 | 8.1 × 10−3 | 0.25 | 1.8 × 10−2 | 0.63 | 2.3 × 10−2 | Pulsar | Pulsar | Yes |
| Her X-1 | 0.09 | 3.3 × 10−3 | 0.10 | 5.7 × 10−3 | 0.82 | 7.9 × 10−3 | Pulsar | Pulsar | Yes |
| OAO 1657 | 0.16 | 6.4 × 10−3 | 0.24 | 1.1 × 10−2 | 0.60 | 1.7 × 10−2 | Pulsar | Pulsar | Yes |
| 4U1822–37 | 0.10 | 5.9 × 10−3 | 0.12 | 8.5 × 10−3 | 0.77 | 1.0 × 10−2 | Pulsar | Pulsar | Yes |
Notes.
a Prob(X) is the median probability across five runs of belonging to class X, where X can be BH, NPNPNS, or pulsar. b These errors are the SDs across five runs of the best BGP model. These errors should be interpreted as an indication of variation across runs.Download table as: ASCIITypeset image
Table A2. KNN Probabilities and Predictions for the Best Model (k = 24)
| System | Prob(BH) a | SD b | Prob(NPNS) | SD | Prob(Pulsar) | SD | Pred. | Class | Correct? |
|---|---|---|---|---|---|---|---|---|---|
| LMC X-3 | 0.67 | 2.1 × 10−2 | 0.31 | 2.2 × 10−2 | 0.02 | 1.9 × 10−3 | BH | BH | Yes |
| LMC X-1 | 0.71 | 1.9 × 10−2 | 0.25 | 1.7 × 10−2 | 0.05 | 4.5 × 10−3 | BH | BH | Yes |
| MAXI J1535–571 | 0.56 | 1.5 × 10−2 | 0.42 | 1.4 × 10−2 | 0.02 | 2.0 × 10−3 | BH | BH | Yes |
| 4U1630–47 | 0.42 | 2.7 × 10−2 | 0.42 | 2.7 × 10−2 | 0.15 | 1.9 × 10−2 | BH or NPNS | BH | No |
| GX 339–4 | 0.73 | 2.3 × 10−2 | 0.23 | 1.7 × 10−2 | 0.04 | 9.0 × 10−3 | BH | BH | Yes |
| GRS 1739–278 | 0.24 | 1.1×10−2 | 0.69 | 1.4×10−2 | 0.06 | 1.0×10−2 | NPNS | BH | No |
| H1743–322 | 0.32 | 1.4 × 10−2 | 0.50 | 1.5 × 10−2 | 0.17 | 1.1 × 10−2 | NPNS | BH | No |
| MAXI J1820+070 | 0.47 | 9.7 × 10−3 | 0.44 | 9.1 × 10−3 | 0.10 | 7.9 × 10−3 | BH | BH | Yes |
| GRS 1915 | 0.15 | 1.5 × 10−2 | 0.71 | 2.0 × 10−2 | 0.13 | 1.6 × 10−2 | NPNS | BH | No |
| Cyg X-1 | 0.68 | 1.5 × 10−2 | 0.29 | 1.5 × 10−2 | 0.02 | 3.3 × 10−3 | BH | BH | Yes |
| 4U1957+115 | 0.44 | 1.6 × 10−2 | 0.53 | 1.6 × 10−2 | 0.03 | 4.0 × 10−3 | NPNS | BH | No |
| Cyg X-3 | 0.06 | 1.0 × 10−2 | 0.21 | 1.6 × 10−2 | 0.74 | 1.6 × 10−2 | Pulsar | BH | No |
| H0614+091 | 0.38 | 1.8 × 10−2 | 0.58 | 2.0 × 10−2 | 0.03 | 3.8 × 10−3 | NPNS | NPNS | Yes |
| 4U1254–690 | 0.34 | 2.2 × 10−2 | 0.54 | 2.9 × 10−2 | 0.12 | 1.4 × 10−2 | NPNS | NPNS | Yes |
| Cir X-1 | 0.29 | 1.2 × 10−2 | 0.52 | 1.3 × 10−2 | 0.18 | 1.6 × 10−2 | NPNS | NPNS | Yes |
| 4U1608–52 | 0.31 | 1.4 × 10−2 | 0.64 | 1.5 × 10−2 | 0.05 | 4.8 × 10−3 | NPNS | NPNS | Yes |
| Sco X-1 | 0.03 | 8.3 × 10−3 | 0.95 | 1.0 × 10−2 | 0.02 | 4.7 × 10−3 | NPNS | NPNS | Yes |
| H1636–536 | 0.28 | 1.5 × 10−2 | 0.61 | 1.7 × 10−2 | 0.10 | 5.1 × 10−3 | NPNS | NPNS | Yes |
| 4U1700–37 | 0.25 | 1.3 × 10−2 | 0.34 | 1.9 × 10−2 | 0.41 | 2.1 × 10−2 | Pulsar | NPNS | No |
| GX 349+2 | 0.03 | 6.3 × 10−3 | 0.93 | 8.7 × 10−3 | 0.04 | 4.7 × 10−3 | NPNS | NPNS | Yes |
| 4U1705–44 | 0.10 | 5.9 × 10−3 | 0.86 | 9.3 × 10−3 | 0.04 | 4.8 × 10−3 | NPNS | NPNS | Yes |
| GX 9+9 | 0.04 | 1.0 × 10−2 | 0.94 | 1.4 × 10−2 | 0.02 | 4.0 × 10−3 | NPNS | NPNS | Yes |
| GX 3+1 | 0.41 | 1.7 × 10−2 | 0.48 | 1.8 × 10−2 | 0.10 | 9.3 × 10−3 | NPNS | NPNS | Yes |
| GX 5–1 | 0.13 | 1.8 × 10−2 | 0.83 | 1.9 × 10−2 | 0.03 | 8.1 × 10−3 | NPNS | NPNS | Yes |
| GX 9+1 | 0.07 | 1.1 × 10−2 | 0.90 | 1.4 × 10−2 | 0.03 | 6.6 × 10−3 | NPNS | NPNS | Yes |
| GX 13+1 | 0.13 | 1.7 × 10−2 | 0.85 | 1.9 × 10−2 | 0.02 | 3.9 × 10−3 | NPNS | NPNS | Yes |
| GX 17+2 | 0.03 | 5.5 × 10−3 | 0.94 | 8.7 × 10−3 | 0.03 | 4.2 × 10−3 | NPNS | NPNS | Yes |
| Ser X-1 | 0.09 | 7.3 × 10−3 | 0.89 | 7.2 × 10−3 | 0.02 | 2.5 × 10−3 | NPNS | NPNS | Yes |
| HETE J1900.1–2455 | 0.27 | 1.1 × 10−2 | 0.54 | 2.0 × 10−2 | 0.19 | 1.3 × 10−2 | NPNS | NPNS | Yes |
| Aql X-1 | 0.30 | 1.2 × 10−2 | 0.67 | 1.2 × 10−2 | 0.03 | 4.1 × 10−3 | NPNS | NPNS | Yes |
| 4U1916–053 | 0.43 | 1.5 × 10−2 | 0.46 | 8.7 × 10−3 | 0.11 | 1.2 × 10−2 | NPNS | NPNS | Yes |
| Cyg X-2 | 0.12 | 1.3 × 10−2 | 0.86 | 1.6 × 10−2 | 0.03 | 4.3 × 10−3 | NPNS | NPNS | Yes |
| SMC X-1 | 0.13 | 1.5 × 10−2 | 0.25 | 1.5 × 10−2 | 0.63 | 2.3 × 10−2 | Pulsar | Pulsar | Yes |
| LMC X-4 | 0.20 | 1.2 × 10−2 | 0.36 | 1.6 × 10−2 | 0.44 | 1.4 × 10−2 | Pulsar | Pulsar | Yes |
| 1A0535+262 | 0.17 | 1.8 × 10−2 | 0.30 | 1.1 × 10−2 | 0.53 | 2.0 × 10−2 | Pulsar | Pulsar | Yes |
| Vela X-1 | 0.30 | 1.9 × 10−2 | 0.15 | 1.4 × 10−2 | 0.55 | 2.3 × 10−2 | Pulsar | Pulsar | Yes |
| GRO J1008–57 | 0.17 | 8.9 × 10−3 | 0.29 | 7.5 × 10−3 | 0.54 | 9.6 × 10−3 | Pulsar | Pulsar | Yes |
| Cen X-3 | 0.12 | 1.3 × 10−2 | 0.18 | 1.0 × 10−2 | 0.69 | 1.3 × 10−2 | Pulsar | Pulsar | Yes |
| GX 301–2 | 0.22 | 2.2 × 10−2 | 0.07 | 9.3 × 10−3 | 0.71 | 1.9 × 10−2 | Pulsar | Pulsar | Yes |
| 4U1538–52 | 0.12 | 1.0 × 10−2 | 0.24 | 1.6 × 10−2 | 0.63 | 1.7 × 10−2 | Pulsar | Pulsar | Yes |
| 4U1626–67 | 0.11 | 8.5 × 10−3 | 0.28 | 1.9 × 10−2 | 0.60 | 2.0 × 10−2 | Pulsar | Pulsar | Yes |
| Her X-1 | 0.08 | 5.7 × 10−3 | 0.09 | 8.2 × 10−3 | 0.82 | 8.6 × 10−3 | Pulsar | Pulsar | Yes |
| OAO 1657 | 0.14 | 1.0 × 10−2 | 0.25 | 1.2 × 10−2 | 0.61 | 2.1 × 10−2 | Pulsar | Pulsar | Yes |
| 4U1822–37 | 0.09 | 8.1 × 10−3 | 0.11 | 1.3 × 10−2 | 0.79 | 1.3 × 10−2 | Pulsar | Pulsar | Yes |
Notes.
a Prob(X) is the median probability across 10 runs of belonging to class X, where X can be BH, NPNS, or pulsar. b These errors are the SDs across 10 runs of the best value of k. These errors should be interpreted as an indication of variation across runs.Download table as: ASCIITypeset image
Table A3. SVM Probabilities and Predictions for the Best Model (C = 0.655, gamma = 0.585)
| System | Prob(BH) a | SD b | Prob(NPNS) | SD | Prob(Pulsar) | SD | Pred. | Class | Correct? |
|---|---|---|---|---|---|---|---|---|---|
| LMC X-3 | 0.70 | 1.9 × 10−2 | 0.26 | 2.0 × 10−2 | 0.03 | 2.7 × 10−3 | BH | BH | Yes |
| LMC X-1 | 0.72 | 1.5 × 10−2 | 0.21 | 1.6 × 10−2 | 0.07 | 6.7 × 10−3 | BH | BH | Yes |
| MAXI J1535–571 | 0.59 | 2.9 × 10−2 | 0.35 | 2.8 × 10−2 | 0.06 | 1.6 × 10−3 | BH | BH | Yes |
| 4U1630–47 | 0.43 | 6.5 × 10−2 | 0.47 | 5.6 × 10−2 | 0.10 | 2.0 × 10−2 | BH or NPNS | BH | No |
| GX 339–4 | 0.67 | 2.8 × 10−2 | 0.27 | 2.3 × 10−2 | 0.06 | 7.5 × 10−3 | BH | BH | Yes |
| GRS 1739–278 | 0.24 | 1.5 × 10−2 | 0.69 | 1.5 × 10−2 | 0.06 | 8.4 × 10−3 | NPNS | BH | No |
| H1743–322 | 0.31 | 1.7 × 10−2 | 0.53 | 1.7 × 10−2 | 0.15 | 9.6 × 10−3 | NPNS | BH | No |
| MAXI J1820+070 | 0.41 | 1.1 × 10−2 | 0.49 | 1.1 × 10−2 | 0.10 | 7.4 × 10−3 | NPNS | BH | No |
| GRS 1915 | 0.20 | 1.5 × 10−2 | 0.72 | 1.9 × 10−2 | 0.08 | 8.2 × 10−3 | NPNS | BH | No |
| Cyg X-1 | 0.67 | 1.4 × 10−2 | 0.31 | 1.4 × 10−2 | 0.03 | 1.5 × 10−3 | BH | BH | Yes |
| 4U1957+115 | 0.47 | 2.1 × 10−2 | 0.49 | 2.1 × 10−2 | 0.04 | 3.2 × 10−3 | NPNS | BH | No |
| Cyg X-3 | 0.07 | 1.2 × 10−2 | 0.19 | 1.5 × 10−2 | 0.74 | 2.0 × 10−2 | Pulsar | BH | No |
| H0614+091 | 0.37 | 2.1 × 10−2 | 0.60 | 2.2 × 10−2 | 0.04 | 3.7 × 10−3 | NPNS | NPNS | Yes |
| 4U1254–690 | 0.37 | 1.6 × 10−2 | 0.53 | 2.2 × 10−2 | 0.10 | 1.4 × 10−2 | NPNS | NPNS | Yes |
| Cir X-1 | 0.27 | 8.3 × 10−3 | 0.56 | 1.1 × 10−2 | 0.17 | 1.4 × 10−2 | NPNS | NPNS | Yes |
| 4U1608–52 | 0.26 | 1.5 × 10−2 | 0.70 | 1.7 × 10−2 | 0.04 | 2.5 × 10−3 | NPNS | NPNS | Yes |
| Sco X-1 | 0.12 | 7.5 × 10−3 | 0.84 | 8.6 × 10−3 | 0.03 | 3.7 × 10−3 | NPNS | NPNS | Yes |
| H1636–536 | 0.23 | 9.3 × 10−3 | 0.68 | 1.1 × 10−2 | 0.08 | 6.4 × 10−3 | NPNS | NPNS | Yes |
| 4U1700–37 | 0.22 | 1.1 × 10−2 | 0.39 | 2.3 × 10−2 | 0.40 | 1.8 × 10−2 | NPNS or Pulsar | NPNS | No |
| GX 349+2 | 0.11 | 8.8 × 10−3 | 0.83 | 6.2 × 10−3 | 0.06 | 5.2 × 10−3 | NPNS | NPNS | Yes |
| 4U1705–44 | 0.13 | 6.4 × 10−3 | 0.82 | 9.8 × 10−3 | 0.05 | 5.0 × 10−3 | NPNS | NPNS | Yes |
| GX 9+9 | 0.13 | 9.1 × 10−3 | 0.83 | 1.1 × 10−2 | 0.05 | 2.6 × 10−3 | NPNS | NPNS | Yes |
| GX 3+1 | 0.36 | 1.6 × 10−2 | 0.56 | 1.6 × 10−2 | 0.07 | 6.4 × 10−3 | NPNS | NPNS | Yes |
| GX 5–1 | 0.20 | 1.4 × 10−2 | 0.77 | 1.4 × 10−2 | 0.03 | 2.9 × 10−3 | NPNS | NPNS | Yes |
| GX 9+1 | 0.12 | 1.1 × 10−2 | 0.84 | 1.3 × 10−2 | 0.04 | 2.9 × 10−3 | NPNS | NPNS | Yes |
| GX 13+1 | 0.21 | 2.1 × 10−2 | 0.77 | 2.2 × 10−2 | 0.02 | 2.7 × 10−3 | NPNS | NPNS | Yes |
| GX 17+2 | 0.11 | 1.1 × 10−2 | 0.84 | 1.5 × 10−2 | 0.06 | 5.6 × 10−3 | NPNS | NPNS | Yes |
| Ser X-1 | 0.15 | 7.5 × 10−3 | 0.81 | 8.6 × 10−3 | 0.04 | 4.9 × 10−3 | NPNS | NPNS | Yes |
| HETE J1900.1–2455 | 0.26 | 1.4 × 10−2 | 0.57 | 1.8 × 10−2 | 0.18 | 1.3 × 10−2 | NPNS | NPNS | Yes |
| Aql X-1 | 0.23 | 7.8 × 10−3 | 0.73 | 9.5 × 10−3 | 0.04 | 3.8 × 10−3 | NPNS | NPNS | Yes |
| 4U1916–053 | 0.26 | 1.1 × 10−2 | 0.65 | 1.2 × 10−2 | 0.09 | 6.5 × 10−3 | NPNS | NPNS | Yes |
| Cyg X-2 | 0.20 | 1.0 × 10−2 | 0.77 | 1.1 × 10−2 | 0.03 | 1.8 × 10−3 | NPNS | NPNS | Yes |
| SMC X-1 | 0.13 | 1.6 × 10−2 | 0.18 | 1.4 × 10−2 | 0.68 | 2.3 × 10−2 | Pulsar | Pulsar | Yes |
| LMC X-4 | 0.19 | 1.7 × 10−2 | 0.35 | 2.1 × 10−2 | 0.47 | 2.3 × 10−2 | Pulsar | Pulsar | Yes |
| 1A0535+262 | 0.10 | 8.4 × 10−3 | 0.33 | 2.0 × 10−2 | 0.56 | 2.2 × 10−2 | Pulsar | Pulsar | Yes |
| Vela X-1 | 0.26 | 2.9 × 10−2 | 0.11 | 1.1 × 10−2 | 0.63 | 3.0 × 10−2 | Pulsar | Pulsar | Yes |
| GRO J1008–57 | 0.14 | 6.0 × 10−3 | 0.27 | 1.0 × 10−2 | 0.59 | 1.3 × 10−2 | Pulsar | Pulsar | Yes |
| Cen X-3 | 0.11 | 7.8 × 10−3 | 0.14 | 8.2 × 10−3 | 0.75 | 9.0 × 10−3 | Pulsar | Pulsar | Yes |
| GX 301–2 | 0.21 | 2.4 × 10−2 | 0.07 | 6.4 × 10−3 | 0.72 | 2.5 × 10−2 | Pulsar | Pulsar | Yes |
| 4U1538–52 | 0.11 | 5.8 × 10−3 | 0.22 | 1.2 × 10−2 | 0.67 | 1.4 × 10−2 | Pulsar | Pulsar | Yes |
| 4U1626–67 | 0.11 | 7.9 × 10−3 | 0.25 | 1.7 × 10−2 | 0.63 | 2.2 × 10−2 | Pulsar | Pulsar | Yes |
| Her X-1 | 0.07 | 3.5 × 10−3 | 0.08 | 7.8 × 10−3 | 0.85 | 8.8 × 10−3 | Pulsar | Pulsar | Yes |
| OAO 1657 | 0.14 | 8.3 × 10−3 | 0.23 | 1.6 × 10−2 | 0.62 | 2.1 × 10−2 | Pulsar | Pulsar | Yes |
| 4U1822–37 | 0.10 | 7.0 × 10−3 | 0.10 | 1.3 × 10−2 | 0.80 | 1.5 × 10−2 | Pulsar | Pulsar | Yes |
Notes.
a Prob(X) is the median probability across 10 runs of belonging to class X, where X can be BH, NPNS, or pulsar. b These errors are the SDs across 10 runs of the best SVM model. These errors should be interpreted as an indication of variation across runs.Download table as: ASCIITypeset image
Footnotes
- 8
- 9
See Section 4.3 on how these median predictions were computed.
- 10
The SVM predicts that there is an equal probability (within error) that 4U1700–37 is an NPNS or pulsar.
- 11