Ontwikkeling van Figma AI
Ontwikkeling van Figma AI
Figma AI is een verzameling functies, ontworpen om jou te helpen efficiënter en creatiever te werken. Of je nu op zoek bent naar inspiratie, meerdere richtingen wilt verkennen of saaie taken wilt automatiseren; wij ontwikkelen AI om ervoor te zorgen dat jij in je flow blijft. Lees hieronder verder over onze aanpak.
Onze aanpak
De generatieve functies van Figma die ontwerpen genereren, worden aangedreven door kant-en-klare AI-modellen van derden. Sommige AI-functies zoals Visual Search, Asset Search en Add Interactions, zijn geoptimaliseerd met gegevens afkomstig van gratis openbare Community-bestanden. Bezoek voor meer informatie over onze Figma AI-functies onze pagina met AI-functies.
We zijn trots op de AI-functies die we tot nu toe hebben ontwikkeld en zoeken voortdurend naar manieren om je werk verder te versnellen met nieuwe modellen, die efficiënter en effectiever samenwerken met Figma's specifieke concepten en tools. Om deze verbeteringen in praktijk te brengen, moeten we modellen trainen die de ideeën en patronen van ontwerpen beter begrijpen, evenals de indelingen en interne structuur van Figma aan de hand van Figma-content.

Gegevensprivacy en beveiliging
We weten hoe belangrijk jouw gegevens zijn voor jou, je bedrijf en je klanten. Ons modelontwikkelingsproces is ontworpen om je privacy en vertrouwelijke informatie te beschermen.
Voor alle klantgegevens, doen wij het volgende:
- Alle gegevens versleutelen, zowel inactief als bij het verzenden
- Beveiligingsmaatregelen gebruiken om te beschermen tegen ongeautoriseerde toegang tot klantgegevens
- Gepersonaliseerde machtigingen en toegangscontroles voor gebruikers implementeren om te beperken wie je gegevens kan bekijken en toegang kan krijgen
Wanneer we samenwerken met derden om gegevens te verwerken, doen we het volgende:
- Externe modelproviders niet toestaan gegevens te gebruiken die klanten op het Figma-platform uploaden of creëren voor het trainen van hun eigen modellen
- Beperken hoe lang leveranciers gegevens kunnen opslaan. OpenAI en onze andere externe modelproviders slaan gegevens tijdelijk op, of in sommige gevallen helemaal niet, om verzoeken te verwerken en AI-functies mogelijk te maken
We nemen extra stappen om onze modellen te trainen zodat ze algemene ontwerppatronen en Figma-specifieke concepten en tools leren en niet jouw content, concepten en ideeën. We anonimiseren bijvoorbeeld inhoud en verwijderen gevoelige informatie, inclusief uit tekst en afbeeldingen.
Lees hier verder over de beveiligingsprocedures van Figma.
Modeltraining
Hier is een overzicht van de soorten gegevens die we mogelijk gebruiken in onze benadering van AI. Om je privacy te beschermen, nemen we maatregelen om de gegevens die we gebruiken voor het trainen van AI-modellen te anonimiseren en te aggregeren.
We gebruiken geen accountgegevens van Figma for Education of Figma for Government voor het trainen van modellen.
Inhoudsgegevens
Het delen van content van je klant met Figma voor AI-modeltraining is optioneel. Beheerders kunnen het delen van content van de klant beheren met een nieuwe instelling. Content van de klant omvat materialen die zijn gemaakt in of geüpload naar Figma.
Voorbeelden van contentgegevens:
- Tekst en afbeeldingen
- Opmerkingen en aantekeningen
- Laagnamen en -eigenschappen
Gebruiksgegevens
Gebruiksgegevens zijn niet hetzelfde als content van de klant en hebben betrekking op de manier waarop Figma wordt geopend en gebruikt. jouw content valt echter niet onder de gebruiksgegevens. Deze gegevens worden op een samengevoegde en geanonimiseerde manier gebruikt om je privacy te beschermen.
Voorbeelden van gebruiksgegevens:
- Informatie over hoe de content van je organisatie wordt gebruikt (zoals hoe vaak deze wordt geraadpleegd)
- Technische logboeken en metagegevens
- Telemetriegegevens
AI-instellingen beheren
Beheerders hebben controle over AI-contenttrainingen, die ze kunnen aanpassen met een instelling. Beheerders kunnen deze instelling op elk moment aan- of uitzetten. Met deze instelling beheer je de contenttraining:
- Voor Starter- en Professional-plannen is contenttraining standaard ingeschakeld; beheerders kunnen ervoor kiezen om dit uit te schakelen
- Voor Organization en Enterprise staat contenttraining standaard uit
Dit is een instelling op teamniveau voor Starter- en Professional-plannen en een instelling op organisatieniveau voor Organization- en Enterprise-plannen.
Onze klantovereenkomsten met Organization en Enterprise zijn doorgaans complexer en bevatten specifieke vereisten en beperkingen, daarom hebben we voor die abonnementen een andere standaardinstelling gekozen.
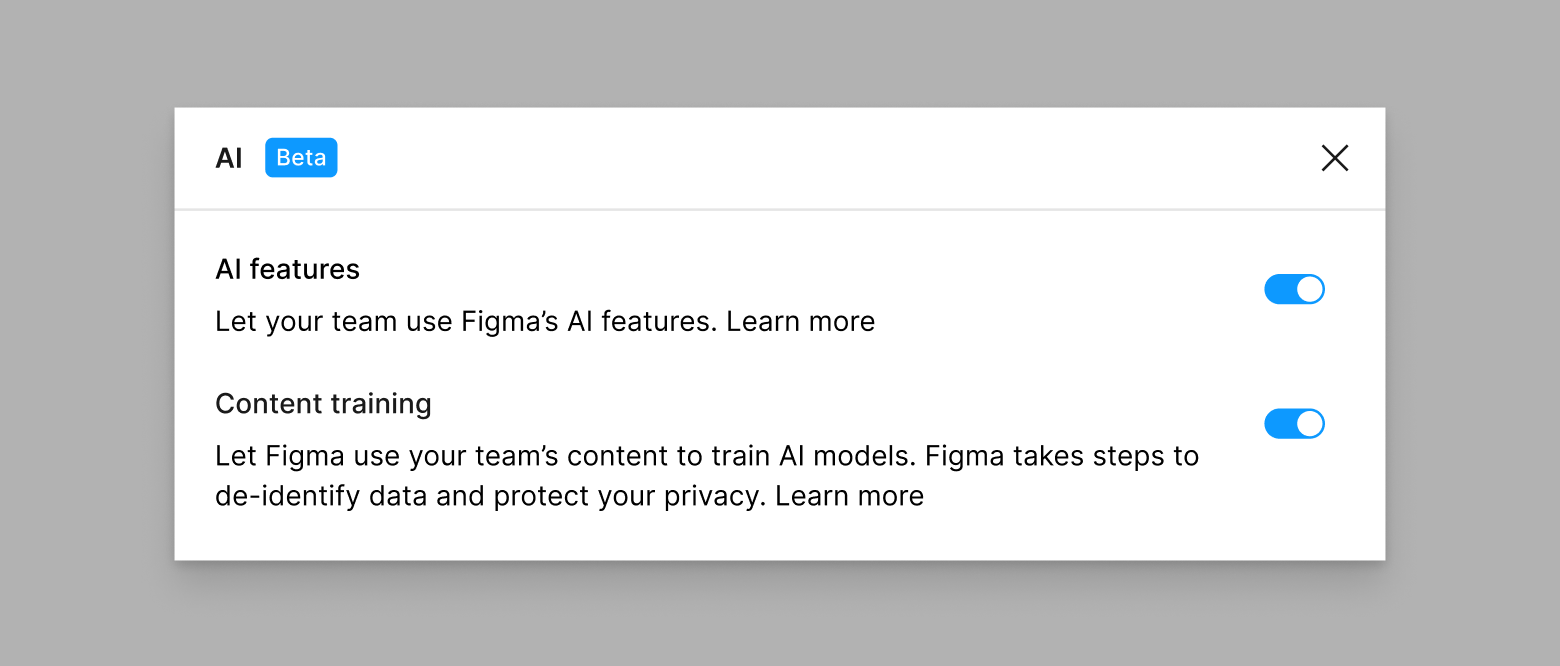
Toen AI-functies zich nog in de bètafase bevonden, kon de toegang tot AI-functies worden aangepast in de beheerdersinstellingen van een team of organisatie. Vanaf 24 juli 2025 zijn de Figma AI-functies algemeen beschikbaar en is deze bèta-instelling verwijderd. Maak je geen zorgen; op abonnementen waar een beheerder eerder de toegang tot AI-functies tijdens de bètafase heeft uitgeschakeld, blijven deze uitgeschakeld tenzij een beheerder ze opnieuw inschakelt. Beheerders met een Enterprise-plan hebben nog steeds extra mogelijkheden om de toegang tot AI-functies te beheren.
Een opmerking voor makers binnen de Figma Community
Samen bouwen en leren met de Figma Community helpt Figma te verbeteren. De gratis bestanden in de Figma Community zijn gelicenseerd onder de CC BY 4.0-licentie, wat betekent dat je ze mag aanpassen en gebruiken, mits je de maker vermeldt. Wat precies wordt beschouwd als juiste vermelding in het geval van AI is echter een veelbesproken onderwerp. We hechten veel waarde aan Figma-gebruikers, dus we willen graag delen hoe we de Community-hulpbronnen gebruiken bij het ontwikkelen van AI-functies.
- Totdat we een beslissing hebben genomen en hierover transparant gaan communiceren, zullen we geen generatieve modellen trainen die ontwerpen genereren via Community-bestanden
- Sommige AI-functies zoals Visual Search, Asset Search, and Add Interactions, zijn geoptimaliseerd met gegevens uit gratis openbare Community-bestanden.
- Wij gebruiken geen betaalde bestanden om AI-modellen te trainen en AI-functies te verbeteren
Veelgestelde vragen
Ontwikkeling van Figma AI
Ontwikkeling van Figma AI
Figma AI is een reeks functies die zijn ontworpen om jou te helpen efficiënter en creatiever te werken. Of je nu op zoek bent naar inspiratie, meerdere richtingen wilt verkennen of saaie taken wilt automatiseren, wij ontwikkelen AI om ervoor te zorgen dat jij in je flow blijft. Lees hieronder meer over onze aanpak.
Onze aanpak
De generatieve functies van Figma die ontwerpen genereren, worden aangedreven door kant-en-klare AI-modellen van derden. Sommige AI-functies, zoals Visual Search, Asset Search en Make Prototype, zijn geoptimaliseerd met gegevens afkomstig van openbare en gratis Community-bestanden. Voor meer informatie over onze Figma AI-functies, bezoek onze pagina met AI-functies.
We zijn trots op de AI-functies die we tot nu toe hebben ontwikkeld en zijn voortdurend op zoek naar manieren om je werk verder te versnellen door nieuwe modellen te ontwikkelen die efficiënter en effectiever werken met de specifieke concepten en tools van Figma Om deze verbeteringen te realiseren, moeten we modellen trainen die de ideeën en patronen van ontwerpen beter begrijpen, evenals de formaten en interne structuur van Figma door middel van de inhoud van Figma.
Gegevensprivacy en beveiliging
We weten hoe belangrijk je gegevens zijn voor jou, je bedrijf en je klanten. Ons modelontwikkelingsproces is ontworpen om je privacy en vertrouwelijke informatie te beschermen.
Voor alle klantgegevens, doen wij het volgende:
- Versleutelen van alle gegevens, zowel inactief als in transit.
- Beveiligingsmaatregelen gebruiken om te beschermen tegen ongeautoriseerde toegang tot klantgegevens
- Implementeren van gepersonaliseerde machtigingen en toegangscontroles voor gebruikers om te beperken wie je gegevens kan bekijken en toegang kan krijgen
Wanneer we samenwerken met derde partijen om gegevens te verwerken, doen we het volgende:
- Externe modelproviders niet toestaan gegevens te gebruiken die klanten uploaden of creëren op het Figma platform voor het trainen van hun eigen modellen
- Beperken hoe lang leveranciers gegevens kunnen opslaan. OpenAI en onze andere externe modelproviders slaan gegevens tijdelijk op, of in sommige gevallen helemaal niet, om verzoeken te verwerken en AI-functies mogelijk te maken
We nemen extra stappen om onze modellen te trainen zodat ze algemene ontwerppatronen en Figma-specifieke concepten en tools leren en niet jouw inhoud, concepten en ideeën. We anonimiseren bijvoorbeeld inhoud en verwijderen gevoelige informatie, inclusief uit tekst en afbeeldingen.
Lees hier meer over de beveiligingsprocedures van Figma.
Modeltraining
Hier is een overzicht van de soorten gegevens die we mogelijk gebruiken in onze AI-aanpak. Om je privacy te beschermen, nemen we maatregelen om de gegevens die we gebruiken voor het trainen van AI-modellen te anonimiseren en te aggregeren.
We gebruiken geen accountgegevens van Figma voor Onderwijs of Figma voor de Publieke sector voor het trainen van modellen.
Inhoudsgegevens
Het delen van je klantinhoud met Figma voor AI-modeltraining is optioneel. Beheerders kunnen het delen van content van de klant beheren met een nieuwe instelling. Content van de klant omvat materialen die zijn gemaakt in of geüpload naar Figma.
Voorbeelden van inhoudsgegevens:
- Tekst en afbeeldingen
- Opmerkingen en aantekeningen
- Laagnamen en eigenschappen
Gebruiksgegevens
Gebruiksgegevens zijn niet hetzelfde als de inhoud van de klant en hebben betrekking op de manier waarop Figma wordt geopend en gebruikt. jouw content valt echter niet onder de gebruiksgegevens. Deze gegevens worden op een verzamelde en geanonimiseerde manier gebruikt om je privacy te beschermen.
Voorbeelden van gebruiksgegevens:
- Informatie over hoe de inhoud van je organisatie wordt gebruikt (zoals hoe vaak deze wordt geraadpleegd)
- Technische logboeken en metagegevens
- Telemetriegegevens
AI-instellingen beheren
Beheerders hebben controle over het gebruik van AI en de contenttrainingen, die ze kunnen aanpassen met twee nieuwe instellingen. Beheerders kunnen deze instellingen op elk moment aan- of uitzetten. Deze instellingen bepalen:
- Toegang tot AI-functies
- Voor alle abonnementen: AI-functies staan standaard op 'aan'
- Contenttraining
- Voor Starter- en Professional-plannen is contenttraining standaard ingeschakeld; beheerders kunnen ervoor kiezen om dit uit te schakelen.
- Voor Organization en Enterprise staat contenttraining standaard op 'uit'
Dit zijn instellingen op teamniveau voor Starter- en Professional-plannen en instellingen op organisatieniveau voor Organization- en Enterprise-plannen.
Onze klantovereenkomsten met Organization en Enterprise zijn doorgaans complexer en bevatten specifieke vereisten en beperkingen, daarom hebben we voor die abonnementen een andere standaardinstelling gekozen. Bovendien zullen deze twee nieuwe instellingen standaard op 'uit' staan voor teams die 'Figma en FigJam AI' hebben uitgeschakeld voor 26 juni 2024.
Een opmerking voor Figma Community-creators
Samen bouwen en leren met de Figma Community helpt Figma te verbeteren. De gratis bestanden in de Figma Community zijn gelicenseerd onder de CC BY 4.0-licentie, wat betekent dat je ze mag aanpassen en gebruiken, mits je de maker vermeldt. Wat precies als de juiste vermelding wordt beschouwd in het geval van AI is echter een veelbesproken onderwerp. We hechten veel waarde aan Figma-creators, dus we willen graag delen hoe we de communitybronnen benaderen bij het ontwikkelen van AI-functies.
- Totdat we een beslissing hebben genomen en onze benadering van attributie transparant hebben gecommuniceerd, zullen we geen generatieve modellen trainen die ontwerpen genereren op Community-bestanden
- Sommige AI-functies, zoals Visual Search, Asset Search en Make Prototype, zijn geoptimaliseerd met gegevens uit gratis, openbare Community-bestanden.
- Wij gebruiken geen betaalde bestanden om AI-modellen te trainen en AI-functies te verbeteren